
I attended the Voice AI Space Amsterdam Meetup — the latest stop in a global tour that has already hit Barcelona, London, Dubai, Paris, and NYC. The Voice AI community is growing fast, and Amsterdam was the natural next stop.

The event was hosted at a venue with impressive production quality — blue-lit stage, professional setup, and a packed room of voice AI builders, researchers, and entrepreneurs.
The Format

The meetup followed a proven formula:
- 5:00 PM — Doors open, networking
- 6:00 PM — Talks and demos from builders
- 7:15 PM — Food, drinks, and more networking
A Global Community

Voice AI Space has already run meetups in London, Paris, Barcelona, Bengaluru, Tokyo, Colombo, New York, San Francisco, Singapore, and Dubai — with Amsterdam as the latest addition. The photos from previous events showed packed rooms across continents. This is a truly global community with serious momentum.

The Talks

Matt Coler — Sarcasm Detection in Voice AI (University of Groningen)

Matt leads a research team at the University of Groningen (Faculty Campus Fryslân) working on one of voice AI’s hardest open problems: getting systems to understand not just what people say, but what they mean.

Sarcasm is a particularly useful lens for probing the limits of pragmatic inference — combining speech, text, and vision to catch what any single channel misses. This is fundamental research that will define how natural future voice assistants feel.
The Multimodal Framework
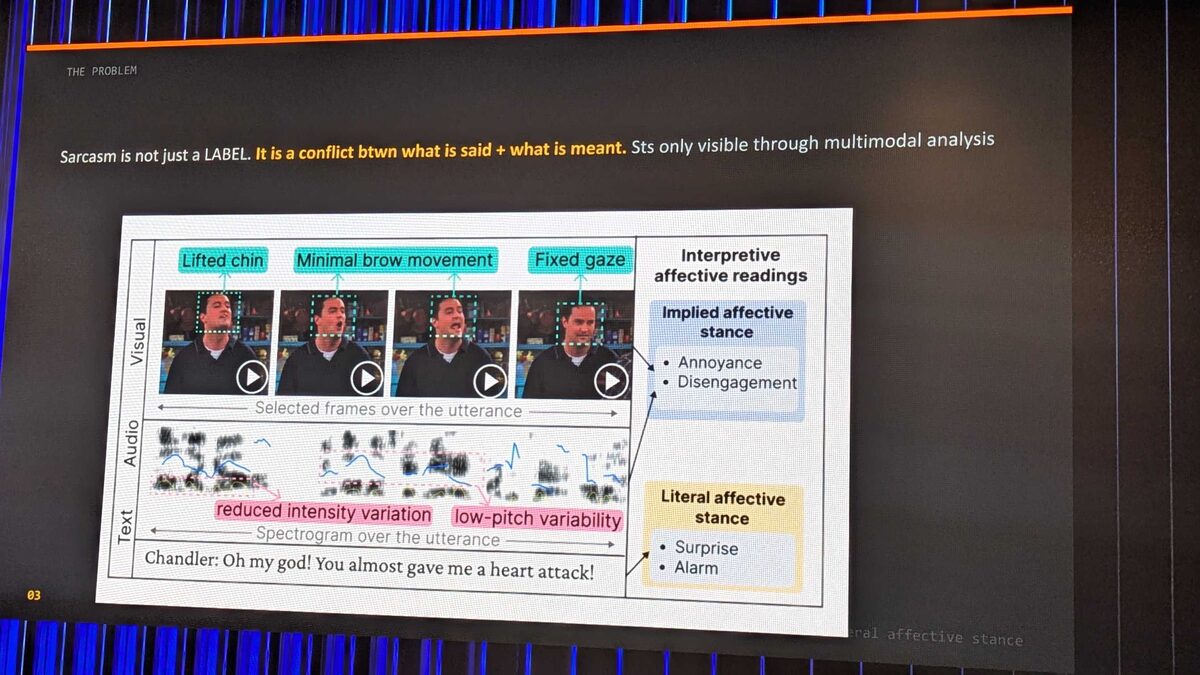
The core insight: sarcasm is not just a label — it is a conflict between what is said and what is meant, only visible through multimodal analysis. Matt showed a framework decomposing utterances into three channels:
- Visual — facial cues (lifted chin, minimal brow movement, fixed gaze) → implied affective stance: annoyance, disengagement
- Audio — spectrogram analysis (reduced intensity variation, low-pitch variability)
- Text — literal content (“Oh my god! You almost gave me a heart attack!”)
The literal reading suggests surprise and alarm. The multimodal reading reveals annoyance and disengagement. Only by combining all three channels can you detect the gap.

Using a Friends clip, Matt demonstrated how identical words from the same speaker carry completely opposite meaning depending on tone and facial expression. This is the fundamental challenge: sarcasm is where the literal reading and intended meaning are furthest apart.
The Structure of the Problem

A key insight: modalities do not just add up — they interact. Matt identified three types of interaction:
- Reinforcement — prosody and words converge, amplifying the signal
- Complementarity — each channel contributes evidence the others cannot
- Incongruity — channels diverge in stance (the hallmark of sarcasm)
The critical takeaway: fusion ≠ concatenation. You need interaction-aware fusion with cross-modal attention to capture these dynamics.
The Research: State-of-the-Art Results
Matt presented results from an ICASSP 2025 ablation study (Raghuvanshi, Gao et al.) showing that every channel contributes, but none is sufficient alone:
| Modality | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|
| Text | 70.14 | 69.12 | 68.84 |
| Audio | 67.29 | 67.28 | 67.24 |
| Visual | 65.41 | 65.32 | 65.20 |
| Text + Visual | 71.90 | 71.89 | 71.86 |
| Audio + Visual | 67.67 | 67.67 | 67.64 |
| Text + Audio | 70.97 | 69.46 | 68.95 |
| Text + Audio + Visual | 75.23 | 75.08 | 74.96 |
The trimodal combination beats any single modality by 6+ percentage points and any bimodal combination by 3+ points — proving that multimodal fusion is essential and not additive, but interactive.

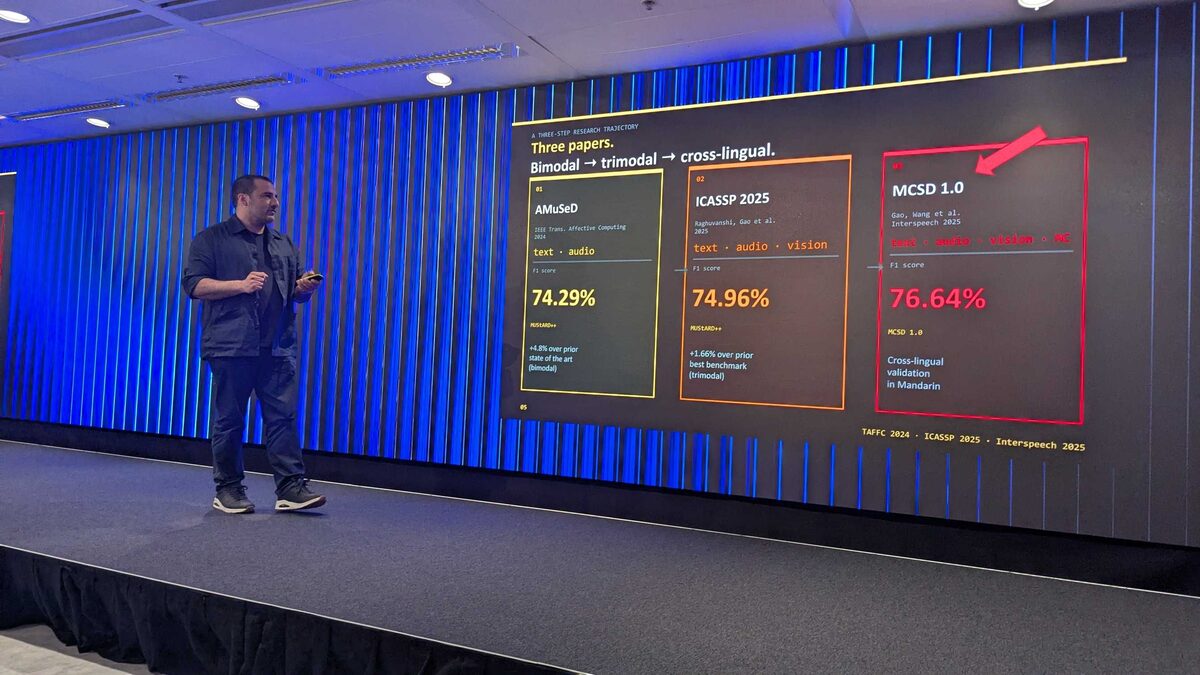
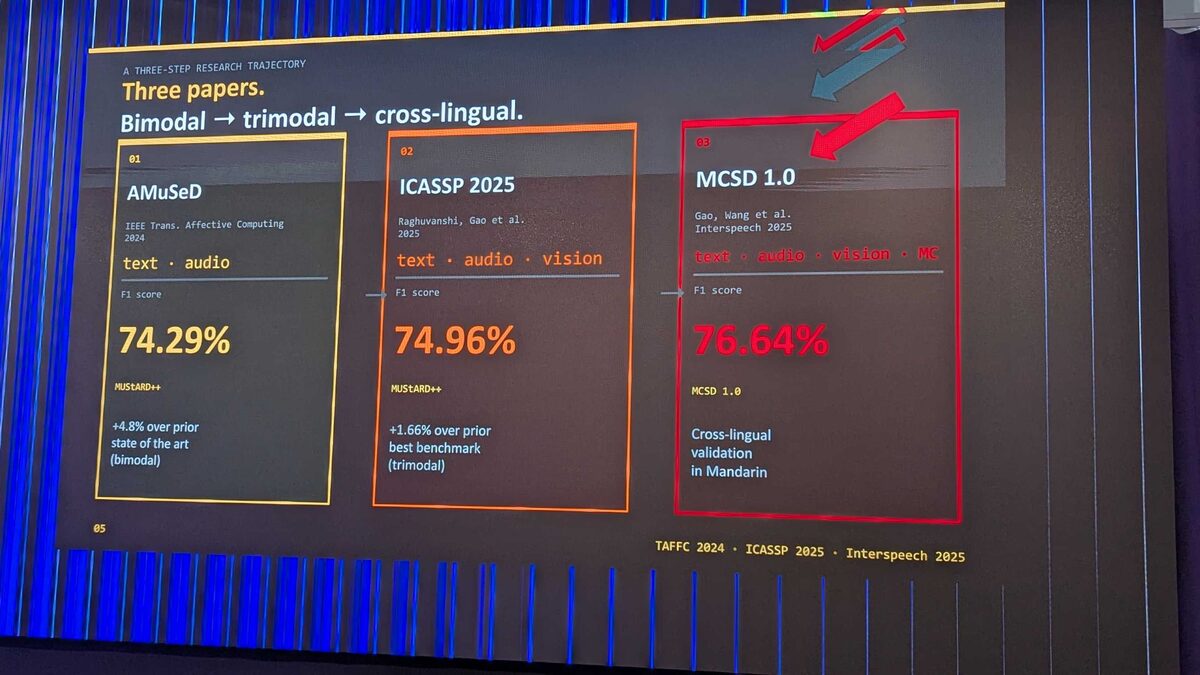
The team’s three-step research trajectory — from bimodal to trimodal to cross-lingual — shows systematic progress:
- AMuSeD (IEEE TAFFC 2024) — text + audio, 74.29% F1 (+4.8% over prior state of the art)
- ICASSP 2025 — text + audio + vision, 74.96% F1 (+1.66% over prior best trimodal)
- MCSD 1.0 (Interspeech 2025) — text + audio + vision + MC, 76.64% F1 with cross-lingual validation in Mandarin

The framework — AMuSeD (Attentive Multimodal Sarcasm Detection) — uses cross-attention so the system interprets acoustic cues relative to lexical content. Sentiment-emotion divergence is modeled as a structured, learnable signal. The core principle: sarcasm exploits the gap between channels.
MCSD 1.0: Cross-Lingual Validation
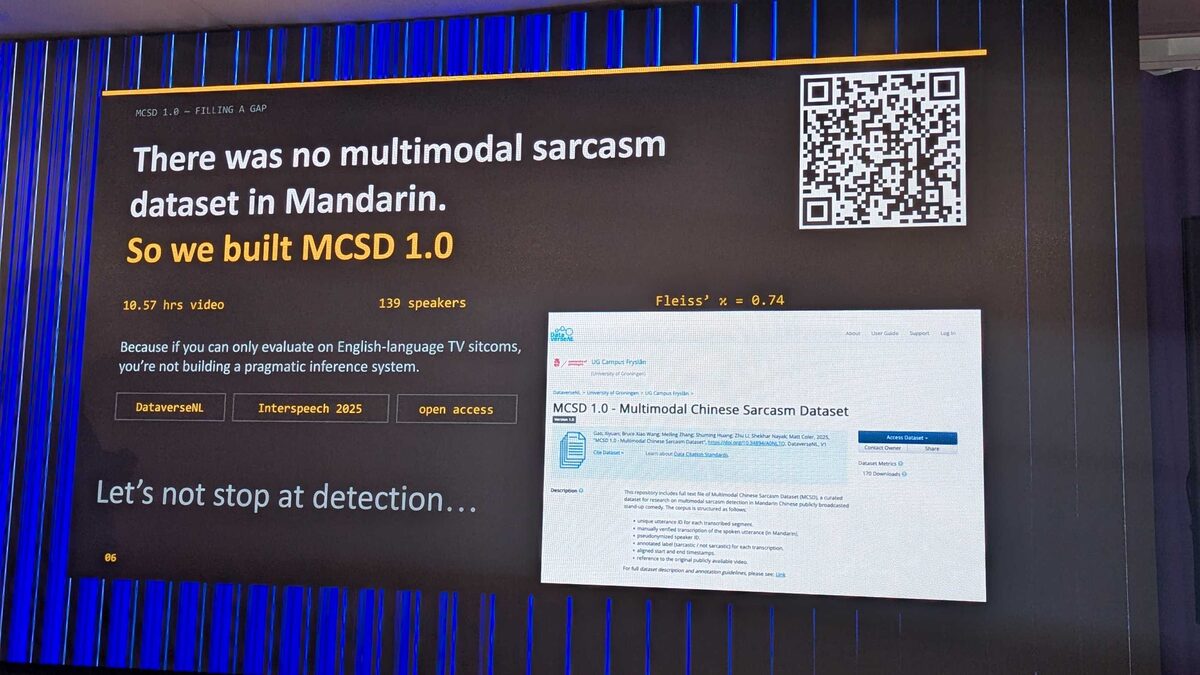

A powerful move: the team built MCSD 1.0 — the first multimodal Chinese sarcasm dataset — because “if you can only evaluate on English-language TV sitcoms, you’re not building a pragmatic inference system.” The dataset contains 10.57 hours of video across 139 speakers, with a Fleiss’ κ of 0.74 (strong inter-annotator agreement). Published at Interspeech 2025 and available as open access on DataverseNL (University of Groningen, UG Campus Fryslân — already 170+ downloads).
The corpus structure includes:
- Unique utterance ID for each transcribed segment
- Manually verified transcription of the spoken utterance (in Mandarin)
- Pseudonymized speaker ID
- Emotional label (sarcastic / not sarcastic) for each transcription
- Aligned start and end timestamps
- Reference to the original publicly available video
Where the Field Is Heading: Explainability

Matt’s final thesis: detection is not enough — the system needs to explain what it understood. Classifying sarcasm is one thing; grounding that classification in evidence is what separates a deployed system from a research benchmark. This is where SarcasmMiner comes in — grounded audio-visual reasoning on the MUStARD++ benchmark.
SarcasmMiner: Grounded Reasoning vs Shortcuts

The case study showed how different models handle the same utterance (“So, this spring, I get to go to the International Space Station. Oh, my word, a trip to the heavens.” — ground truth: Non-Sarcasm):
- SFT Baseline (word-based): Incorrectly predicts sarcasm — “A trip to the heavens” is treated as hyperbolic praise
- GRPO (speaker-based): Also wrong — uses character knowledge as a shortcut (Wolowitz’s comedic personality)
- SarcasmMiner (multi-modal contextual): Correctly predicts non-sarcasm — tone is high-pitched and energetic, facial expression shows genuine awe

Only the multimodal contextual model avoids the trap of using shortcuts (word patterns or character stereotypes) and instead grounds its reasoning in the actual audio-visual evidence.
The Bigger Picture: Beyond Sarcasm


Matt closed with a powerful framing: “We trained ourselves to speak like machines. It’s time machines learned how humans actually speak.” Sarcasm is just one test case — human language is full of non-literal expression:
- Sarcasm: “Oh great, another Monday” — means the opposite
- Hyperbole: “I’ve told you a dozen times” — means “many times”
- Understatement: “It’s a bit warm” said in a heat wave
- Humor: “I am dying” — means “this is very funny”
- Implicature: “It’s cold in here” — means “close the window”
- Irony: “What a beautiful day” said in a storm
The broader mission is pragmatic inference — teaching machines to understand what we mean, not just what we say. Each of these categories exploits a different gap between literal content and intended meaning, requiring different detection strategies and multimodal cues.
The Team: Speech Tech Lab, University of Groningen
The research comes from the Speech Tech Lab at the University of Groningen, led by Dr Matt Coler as Associate Professor, Co-supervisor, and Director of the MSc Speech Technology program. The team includes Dr Shekhar Nayak (Assistant Prof, Co-supervisor), Ms Xiyuan Gao (PhD Candidate, defense June 2025), and Mr Zhu Li (PhD Candidate). Their published work spans AMuSeD, MCSD 1.0, SarcasmMiner, IEEE TAFFC, and Interspeech 2025.
Beyond Sitcoms: The Real-World Stakes

Matt made the case that sarcasm detection is not just an academic exercise — it has real legal and political consequences. He used the Mueller Report (Appendix C, Question II(d)) as a case study: a statement claimed to be made “in jest and sarcastically, as was apparent to any objective observer” — yet the video shows a straight face, no laughter, and no sarcastic cues.

The conclusion: the multimodal record contradicts the claim. A system that reliably detects pragmatic stance from voice, face, and context would resolve this — turning sarcasm detection from a curiosity into a tool for justice.
When a two-year federal investigation hinges on whether something was sarcastic, you realize how important this detection problem truly is.

Thomas Kluiters — Reson8: Customizing Speech Recognition for the Real World
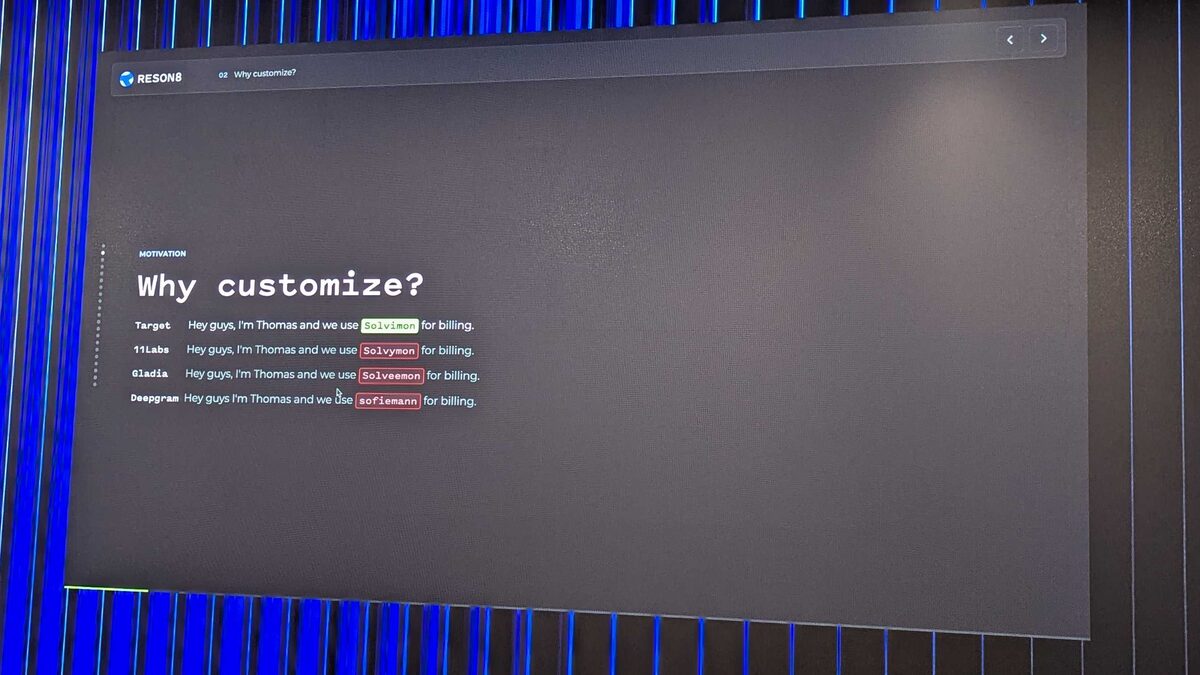
Thomas Kluiters, Head of AI at Reson8 (a local Amsterdam voice AI company), delivered a deeply practical talk on customizing speech recognition for production use cases. His opening example was immediately relatable: the word “Solvimon” (a billing platform) transcribed by four different ASR providers:
| Provider | Output |
|---|---|
| Target | Solvimon ✅ |
| 11Labs | Solvymon ❌ |
| Gladia | Solveemon ❌ |
| Deepgram | sofiemann ❌ |
The message: off-the-shelf ASR fails on domain-specific vocabulary. If your product relies on correctly recognizing proper nouns (company names, medication names, technical terms), you must customize.

Healthcare: Where ASR Errors Are Dangerous
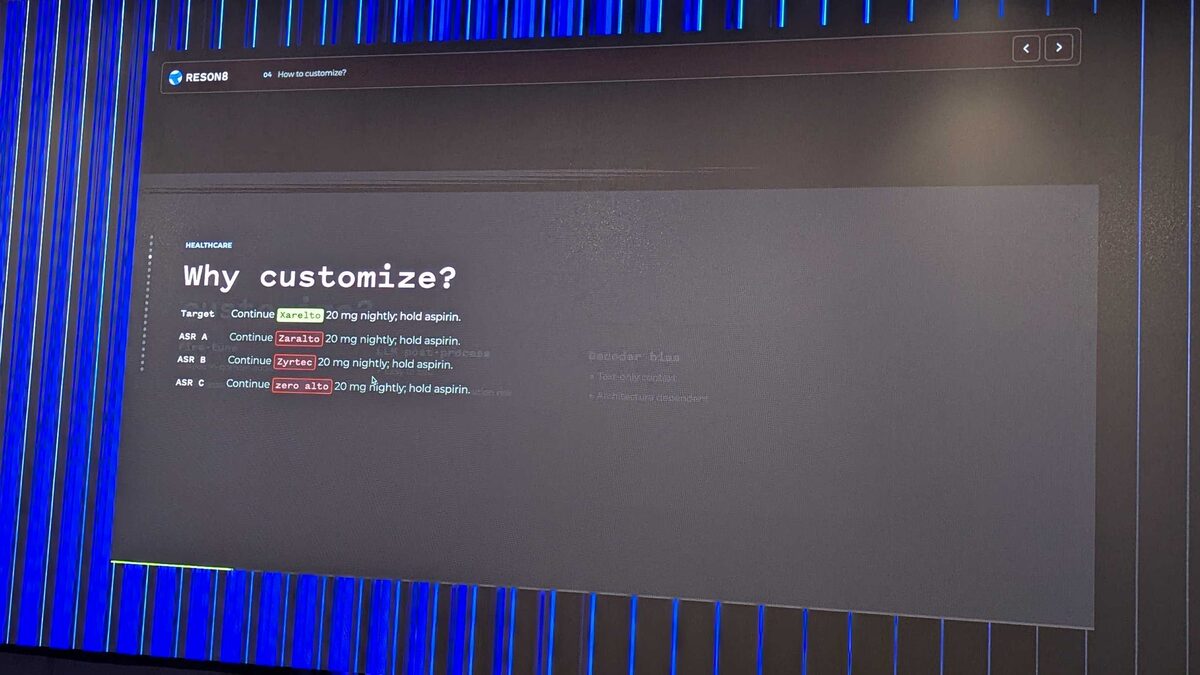
Thomas drove the point home with a healthcare use case: the medication Xarelto (a blood thinner) transcribed by three ASR systems:
- ASR A: “Zaralto” — wrong but close
- ASR B: “Zyrtec” — completely different medication (an antihistamine)
- ASR C: “zero alto” — nonsensical
In a clinical setting, mistaking a blood thinner for an antihistamine is not a transcription error — it is a patient safety risk. This is why customization matters.
Three Approaches to Customization

Thomas compared three approaches:
| Approach | Pros | Cons |
|---|---|---|
| Fine-tune | Best accuracy | Needs in-domain audio; risk of catastrophic forgetting |
| LLM post-process | Easy to add | Latency and hallucination risk |
| Decoder bias | Text-only context | Architecture dependent |
LLM Post-Processing: Prompt After ASR
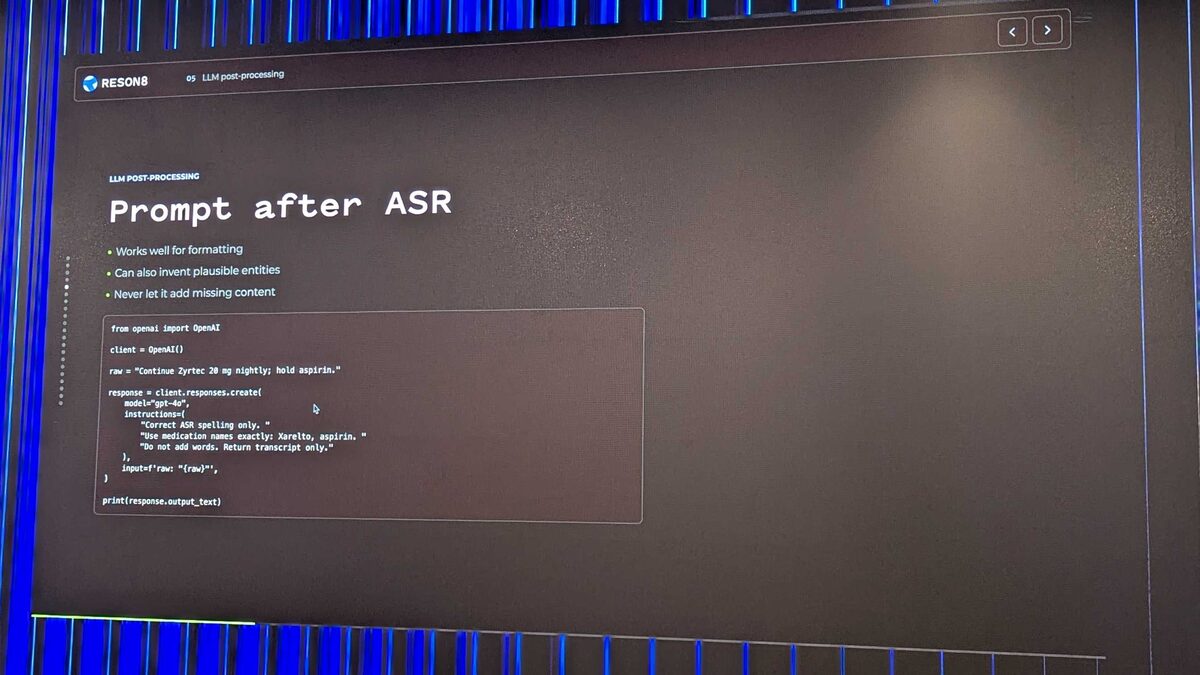
Thomas showed a practical code example: using GPT-4o to correct ASR output specifically for medication names. The prompt instructs the model to “Correct ASR spelling only. Use medication names exactly: Xarelto, aspirin. Do not add words. Return transcript only.”
Key trade-offs:
- ✅ Works well for formatting
- ⚠️ Can invent plausible entities (hallucination)
- ❌ Never let it add missing content

Model Architectures for ASR

Thomas provided a taxonomy of current ASR architectures, starting with the fundamentals: encoders encode what is heard, decoders decode what is said, and customization is generally applied at the decoder layer.
The key architectural parameters:
- Whisper large-v3 (balanced): Encoder 637M params, Decoder 907M params — robust offline baseline, prompting supports short context only, long prompts unreliable
- NVIDIA Parakeet-TDT-0.6B-v3 (encoder heavy): Encoder 609M params, Decoder only 17M params — fast encoder-heavy ASR with efficient decoder search, biasing happens in search (FastConformer architecture with SpecAug → 8x Conv Subsampling → Linear → Dropout → Conformer Blocks)
- Qwen3-ASR-1.7B / Voxtral (decoder heavy): Small encoder, large decoder — leverages LLM text generation capabilities for transcription
- Voxtral-Mini-3B (speech-conditioned LLM): Full language model conditioned on speech input
Each architecture implies different customization strategies. Encoder-heavy models like Parakeet respond better to decoder biasing (vocabulary boosting at search time), while decoder-heavy models are more amenable to prompt-based corrections. Balanced models like Whisper support short prompts but break with complex instructions.
The clear message from Reson8: the future of production voice AI is not just about picking the best model — it is about building customization pipelines that adapt general-purpose ASR to your specific domain, vocabulary, and safety requirements.
ai-coustics — Real-Time Audio Intelligence


ai-coustics presented their approach to making voice AI production-ready through real-time audio intelligence. Their pitch cuts straight to the core problem: most voice AI works brilliantly in controlled lab environments but falls apart in the real world — background noise, reverb, cross-talk, and varying microphone quality all degrade performance. ai-coustics bridges that gap with audio enhancement that runs in real-time, making downstream voice AI systems (ASR, voice agents, telephony) significantly more robust.
Ahmed Mamdouh Khalil — The Rise and Fall of ASCENSCIA
A refreshingly honest post-mortem: Ahmed shared lessons learned from building an AI Voice Assistant for scientific labs. The “rise and fall” framing is rare in tech meetups — most people only share success stories. Understanding why voice AI products fail in specialized domains is just as valuable as knowing what works.
Kevin Litnaël — Live Vibe-Coding a Voice AI Agent with Vapi
Kevin Litnaël, Account Executive at Vapi, delivered the most interactive session of the evening: building a fully functional voice AI agent live on stage using Claude and Vapi’s platform.
The agent was configured with GPT-4.1 Mini as the LLM, Deepgram nova-3 for transcription, and the “Elliot” voice — running at approximately $0.09/min with 1,220ms first-response latency. Kevin walked through the full Vapi dashboard showing how each component plugs together.
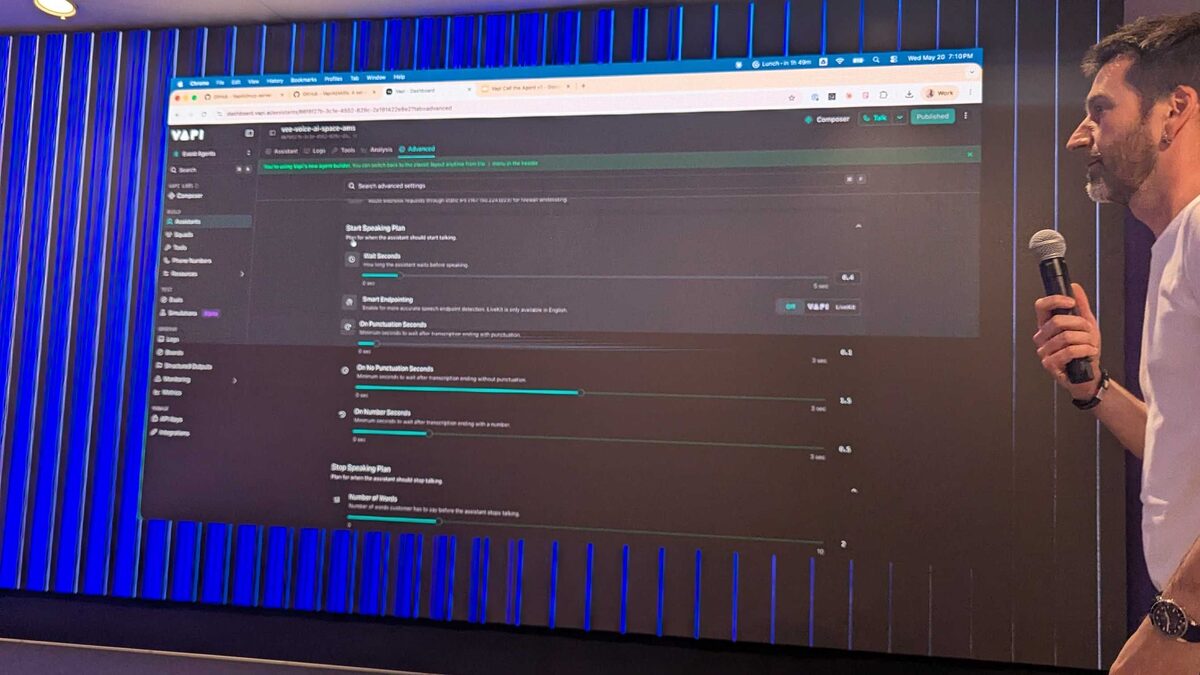
He then fine-tuned the conversational dynamics: configuring Smart Endpointing (powered by LiveKit), stop speaking plan parameters (Number of Words: 2, Voice Seconds: 0.5, Back Off Seconds: 0.8), and voicemail detection.
The highlight was the live demo: Kevin gave the audience a real Dutch phone number (+31 97010208315) and invited everyone to call the agent simultaneously — proving the platform handles concurrent calls gracefully. Vapi is emerging as a leading platform for building voice-first AI agents with minimal infrastructure.
Phanos Anastasiou — ChickyTutor Demo
Phanos demoed ChickyTutor, an AI language tutor designed for everyone. Voice-first language learning is a natural fit — pronunciation feedback, conversational practice, and real-time correction all benefit enormously from speech AI.
Deepak Singla — Fini Multi-Modal AI Agent

Deepak Singla, Co-founder and CEO of Fini, demonstrated their multi-modal AI agent built for enterprise fintech support. The live demo showcased a fascinating use case: YEGO, a scooter rental company using Fini’s voice agent to handle customer calls for scenarios like remote unlock, unpaid fines, blocked accounts, missing payment methods, and faulty credit resolution.
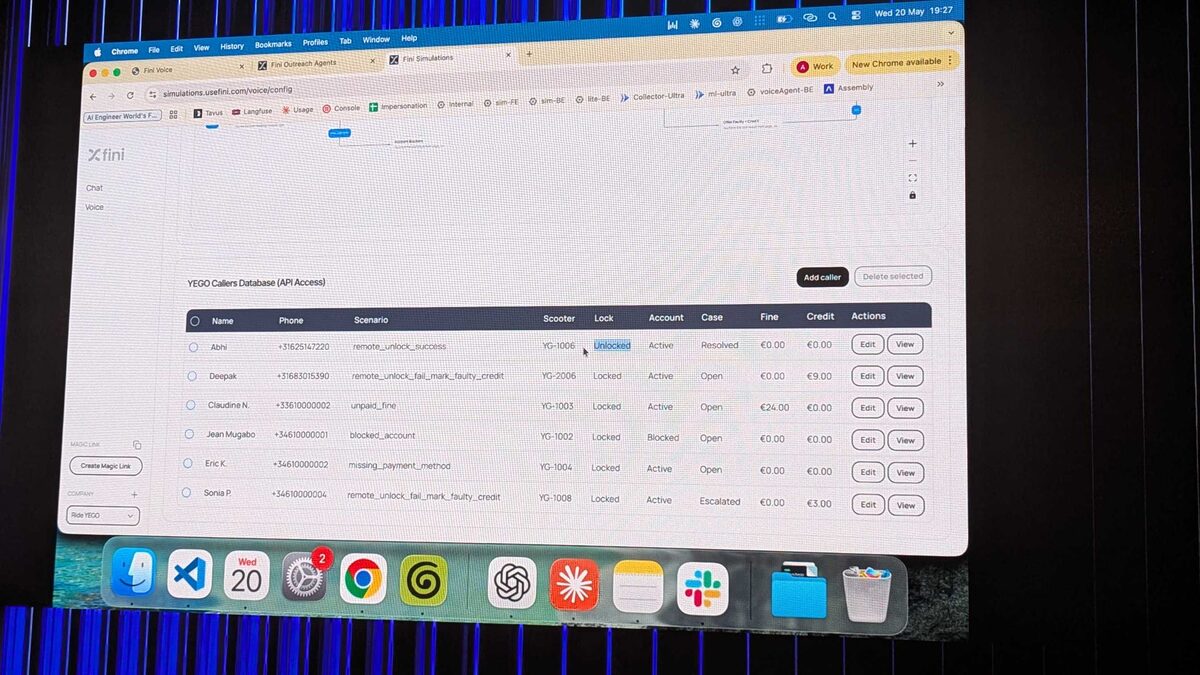
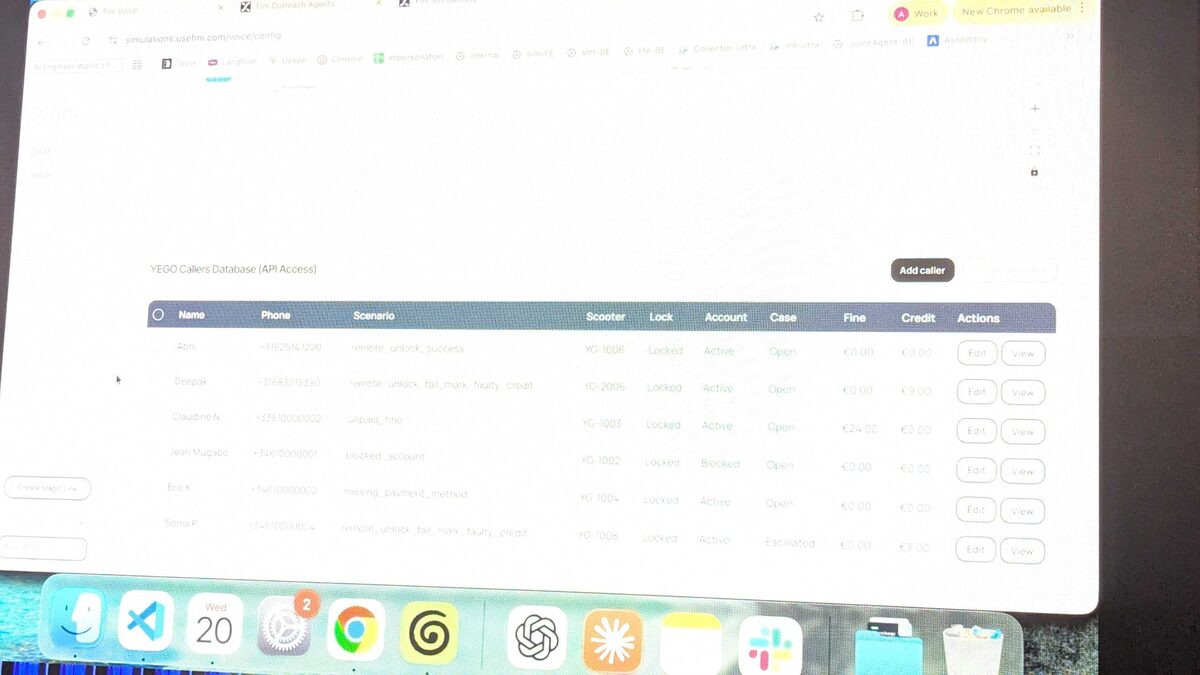
The simulation environment at simulations.usefini.com showed how Fini tests voice agents against a database of caller personas — each with different phone numbers, scooter IDs, lock states, account statuses, and credit balances. This kind of structured evaluation is exactly what enterprise voice AI deployments need.
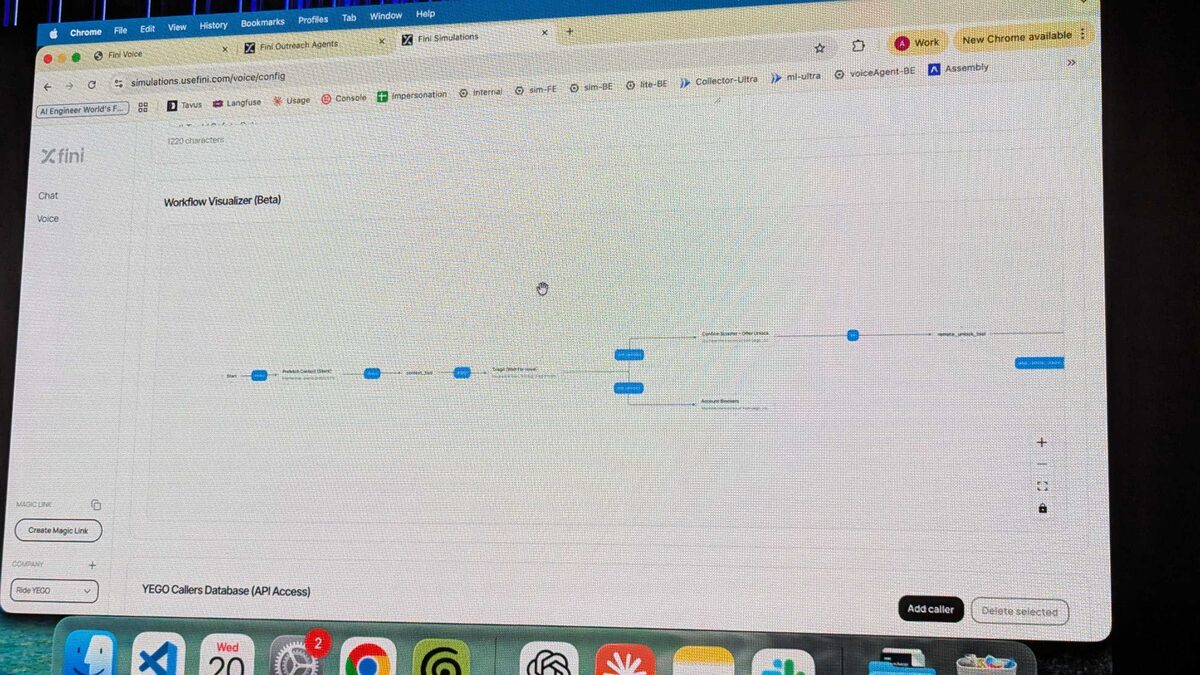
The Workflow Visualizer (in beta) revealed Fini’s agent architecture: a visual pipeline starting from initial contact, through context gathering, target state classification, then branching into specialized handlers (Account Blockers, Custom Router) before executing actions like remote_unlock_tool. This visual approach to voice agent orchestration makes complex multi-turn conversations debuggable and maintainable.
Voice AI Space: The Central Hub

voiceaispace.com positions itself as the central hub for everything Voice AI — covering products, news, knowledge, jobs, and events. With meetups now running across 6+ cities globally, they are building real community infrastructure for the voice AI ecosystem.
Key Takeaways
- Voice AI is maturing fast — from research labs to production deployments in fintech, education, and enterprise support
- Sarcasm and pragmatic inference remain unsolved — understanding intent beyond words is the next frontier
- European voice AI is thriving — local companies like Reson8 building competitive speech recognition
- Honest failure stories create more value than polished success narratives at meetups
- Vibe-coding voice agents is now possible — tools like Vapi + Claude enable rapid prototyping on stage
The voice AI space (pun intended) is one of the fastest-growing niches in AI right now. With multimodal models adding native speech capabilities and latency dropping below human perception thresholds, we are approaching a tipping point where voice-first interfaces become the default for many applications.



