At the Red Hat Tech Day Netherlands (June 2026), a Red Hat engineer delivered a comprehensive deep dive into vLLM inference optimizations — from fundamental KV caching through quantization to distributed multi-node serving. This was not a marketing talk; it was a production engineering session with real benchmarks, real cluster configurations, and real model deployment data.
I captured the entire session and here is everything you need to know about running LLMs efficiently on OpenShift AI.
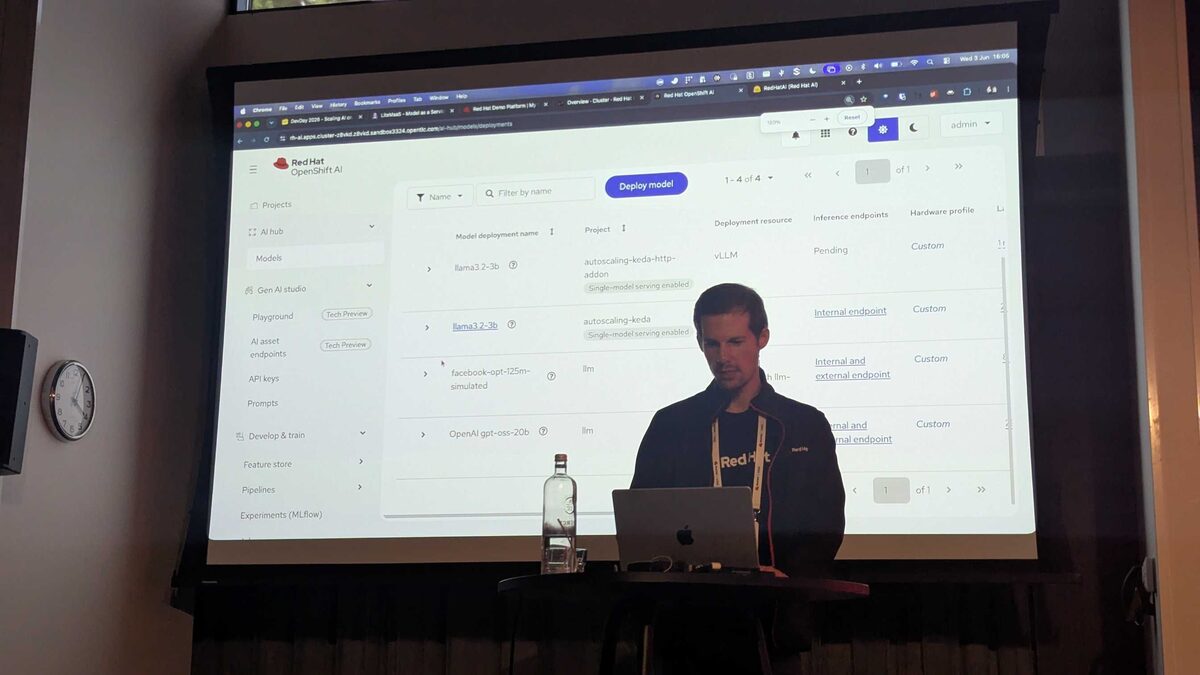
vLLM: Two Core Concepts
The talk structured vLLM around two pillars:
- Inference Optimizations — Making individual model serving faster and leaner
- Distributed Inference — Scaling across multiple GPUs and nodes
KV Cache: The Foundation of Fast Inference
Every transformer token generation requires attending to all previous tokens. Without optimization, this means recomputing the full attention matrix every step.
KV Cache stores the Key and Value tensors from previous tokens, avoiding redundant computation for the prefix. This is the single most impactful optimization for autoregressive generation.
Static vs Continuous Batching
- Static batching: All sequences in a batch must wait for the longest to complete
- Continuous batching: Fill empty slots with new sequences as others finish — dramatically improving throughput
vLLM implements continuous batching natively, ensuring GPU utilization stays high even with variable-length requests.
Pre-Optimized Models
vLLM comes with first-class optimization support for:
- Llama (Meta)
- Qwen (Alibaba)
- Gemma (Google)
- Mistral
- DeepSeek
- Phi (Microsoft)
- Molmo
- Granite (IBM/Red Hat)
- Nemotron (NVIDIA)
Quantization: Fit More, Lose Almost Nothing
Supported Formats
| Format | Description | |



