RoachFest London 2026, hosted by Cockroach Labs at Convene, 22 Bishopsgate, spent a full day on a theme that is increasingly hard to separate from database architecture itself: how do you operate without fear, build with confidence, and adapt to the AI era when the database is the thing everything else depends on.
Workshop: Transactional Vector Search and RAG
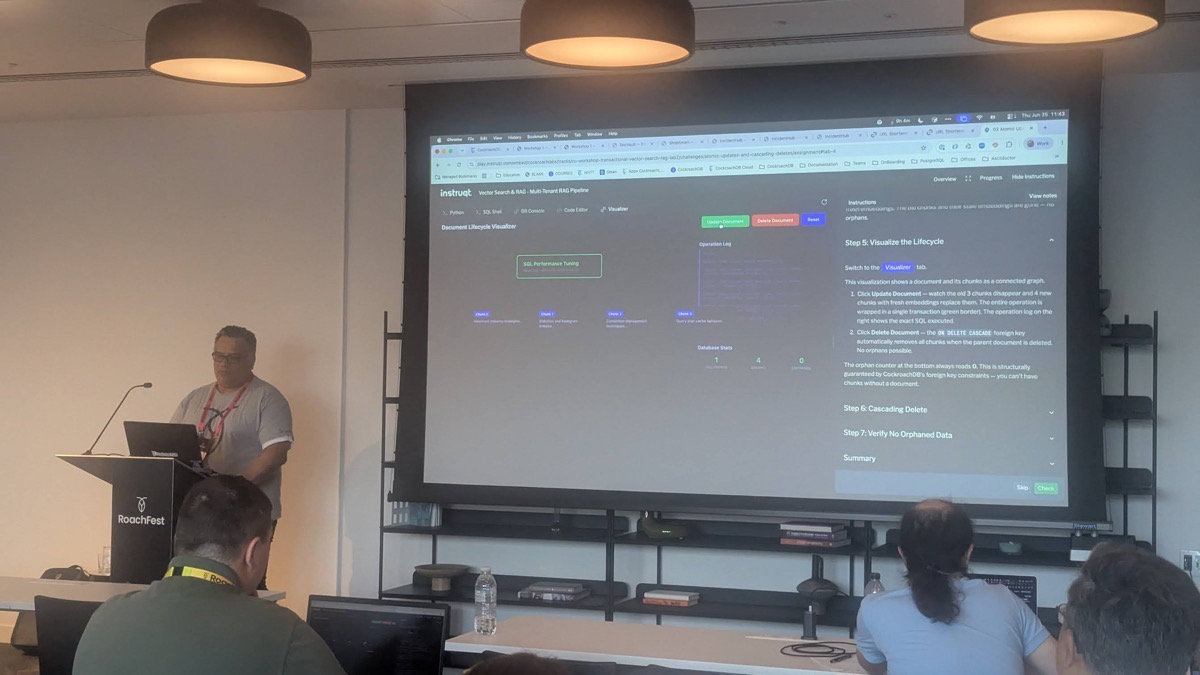
The hands-on track covered CockroachDB fundamentals — Raft consensus, ACID transactions, automatic data distribution, multi-region design, PostgreSQL compatibility — but the session that stood out was the lab on transactional vector search and RAG. The exercise made a point that is easy to state and genuinely hard to get right in most AI stacks: when a document is updated, its old embeddings should disappear and new ones should appear as a single atomic operation, with foreign-key cascades guaranteeing zero orphaned chunks.
That is the practical case for keeping operational data and embeddings in the same database rather than bolting a separate vector store onto an existing application. A lot of RAG pipeline architectures treat consistency between the source-of-truth data and the vector index as an eventual-consistency problem to be managed with reconciliation jobs. Doing it transactionally instead removes an entire category of “why does the RAG answer reference a document that no longer exists” bugs.
Spencer Kimball: The Cost Tax and What CockroachDB Becomes
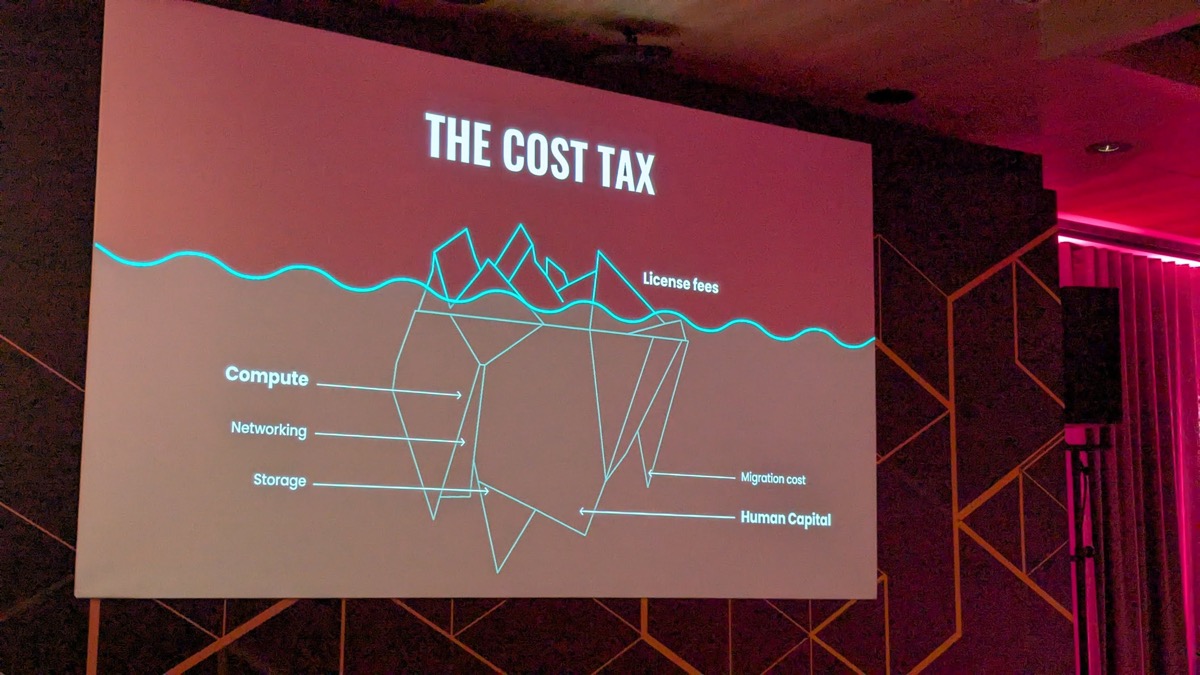
Spencer Kimball opened the main stage with a framing worth stealing for any infrastructure cost conversation: the cost tax. License fees are the visible tip of the iceberg; underneath sits compute, networking, storage, migration cost, and human capital — the costs that never show up on a vendor’s pricing page but dominate the actual total cost of ownership. It is the same argument behind why so many “cheaper” database migrations end up more expensive than staying put, once the hidden layer is counted.

The more forward-looking part of the keynote was Kimball’s architecture for what CockroachDB becomes: an agent layer sitting on top of virtual databases, which sit on top of physical clusters, which sit on a shared storage foundation. The framing treats AI agents as first-class database tenants — each agent gets what looks like its own elastic virtual database, backed by the same distributed, consistent, horizontally-scalable foundation everything else runs on. That is a meaningfully different bet than treating agent memory as “just another RAG store bolted onto the app” — it is closer to building AI agents as first-class operators with the database itself managing their state boundaries.
Kimball backed the vision with customer logos that do not tolerate downtime as an abstraction: Booking.com, Nvidia, DoorDash, Roblox, Cisco, CoreWeave, SpaceX, and OpenAI were all listed under “mission-critical has always been our focus” — a reasonable signal that distributed SQL adoption at this scale is not hypothetical anymore.
Form3: Multi-Cloud Resilience for Real-Time Payments
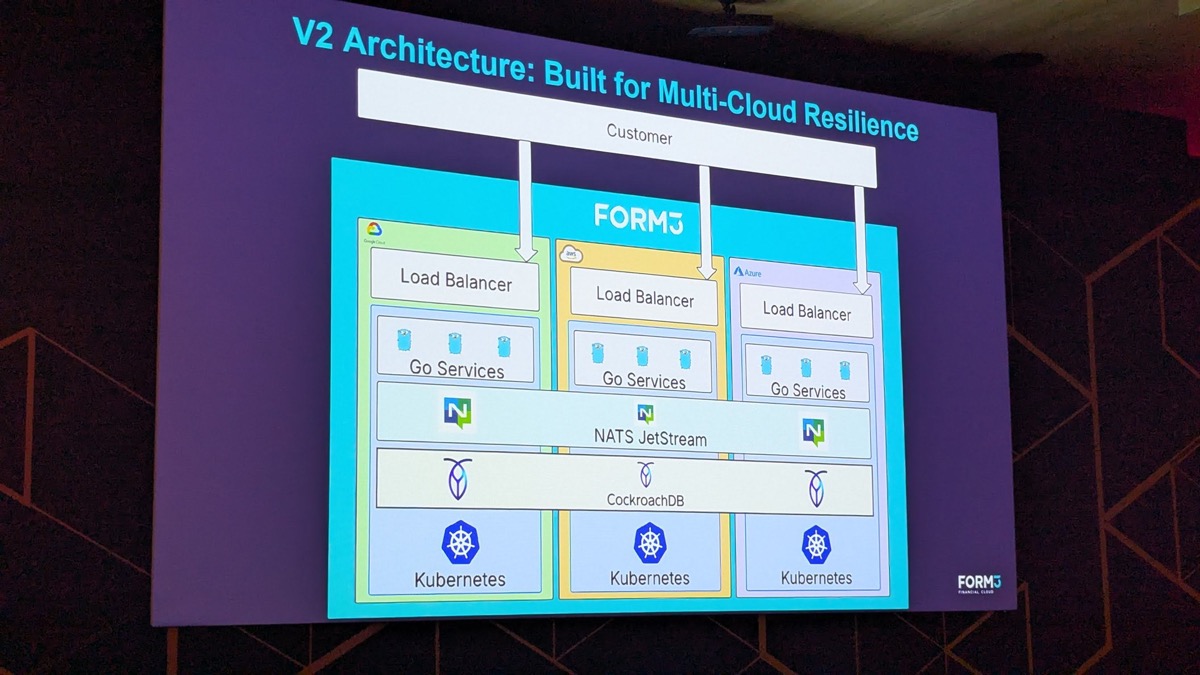
Kevin Holditch presented Form3’s V2 architecture, built explicitly for multi-cloud resilience: identical stacks — load balancer, Go services, NATS JetStream, CockroachDB, Kubernetes — replicated across Google Cloud, AWS, and Azure. The point of the architecture is not efficiency, it is survivability: if one cloud provider has an outage, a real-time payments platform kept operational through it, rather than joining the outage’s blast radius. CockroachDB’s multi-region consistency model is what makes running the same logical database across three different cloud providers a coherent design rather than three separate databases pretending to be one.
Primer: Zero-Downtime Migration Under Live Payment Traffic

Vik Bhatti walked through Primer’s migration of a live payments platform to CockroachDB, starting from the write-capacity wall every growing single-writer database eventually hits. The slide laid out the two conventional options and why both failed: scaling up the one writer runs into a hard ceiling where every resize risks downtime, and self-managed sharding means building and running your own routing, rebalancing, and failover — and even that would not have been enough, since their largest new merchant alone would have exceeded a single shard’s capacity.
The migration pattern that got them out from under both dead ends was pragmatic rather than clever: don’t copy it, archive it. Hot data lives in CockroachDB and is checked first; cold data (old payments) moves to S3 and is only read back on a cache miss, with a write-back path that keeps the hot store as the single source of truth going forward. “We let the old data sleep, and woke it only when a customer knocked” is a good one-line summary of a pattern that generalizes well beyond payments — most datasets have a hot fraction that needs strong consistency and a cold majority that does not.
Major Tim Peake: Operating Without Fear

The closing keynote came from an unexpected direction: Major Tim Peake, drawing on space mission operations to talk about what resilience actually requires under pressure. The parallel to distributed systems is closer than it first sounds — a space mission has no rollback, no “let’s patch it next sprint,” and a failure mode that cannot be debugged after the fact from a comfortable office. The ability to adapt in real time, with the plan you have rather than the plan you wished you had, is exactly what separates teams that survive an incident from teams a postmortem gets written about.
Compliance and Governance Context
RoachFest’s resilience and multi-region themes connect directly to a compliance reality most attendees are already navigating: data residency requirements in multi-cloud environments and the broader push toward documented AI agent compliance under frameworks like DORA and GDPR. A database that can guarantee where data physically lives, region by region, while staying strongly consistent is not just an engineering nicety — for payments and other regulated workloads, it is close to a prerequisite.
Thanks
A big thank you to the entire Cockroach Labs team, the speakers, instructors, and customers who made the day worthwhile — including Igor Stanko, Rob Reid, Anna Eriksson, Felipe Gutierrez Cruz, Matt Gardner, Nathan Zamecnik, Jordan Legg, Takara AI, and AuthZed for the conversations throughout the day — and to AWS for sponsoring the event.
Related Reading
- Enterprise RAG Architecture Patterns at Scale
- Vector Databases on Kubernetes: Qdrant vs Milvus vs pgvector
- Data Residency in Multi-Cloud Kubernetes
- Building AI Agents as Kubernetes Operators
About the Author
I am Luca Berton, AI and Cloud Advisor. I work at the intersection of distributed systems, platform engineering, and enterprise AI deployments. Book a consultation.
