
At Red Hat Summit 2026 in Atlanta, the Red Hat AI Innovation Team presented one of the most practical demos I saw at the event: Training Hub, a unified Python API for modern LLM post-training. No more stitching together five different libraries to fine-tune a model — Training Hub gives you one consistent interface for every training algorithm you need.
The repository is open source: github.com/Red-Hat-AI-Innovation-Team/training_hub
What Training Hub Enables

Training Hub provides a single API surface to access different training algorithms. The demo walked through four distinct fine-tuning approaches, all using the same import pattern:
Supervised Fine-Tuning (SFT)

Full-parameter fine-tuning on instruction data. The code is remarkably clean:
from training_hub import sft
sft(
model_path="ibm-granite/granite-4.1-8b",
data_path="./my_data.jsonl",
ckpt_output_dir="./sft_output",
num_epochs=3,
effective_batch_size=64,
learning_rate=5e-6,
max_seq_len=8192,
)
One function call. No boilerplate. No trainer configuration classes. Just the parameters that matter.
LoRA Fine-Tuning

Parameter-efficient fine-tuning with low-rank adapters — the same unified API, different import:
from training_hub import lora_sft
lora_sft(
model_path="google/gemma-3n-E4B-it",
data_path="./my_data.jsonl",
ckpt_output_dir="./lora_output",
lora_r=16,
lora_alpha=32,
num_epochs=3,
learning_rate=1e-4,
max_seq_len=2048,
)GRPO (Group Relative Policy Optimization)

Full-parameter reinforcement learning from verifiable rewards — the algorithm behind much of the recent reasoning model progress:
from training_hub import grpo
grpo(
model_path="Qwen/Qwen3-4B",
data_path="./my_data.jsonl",
ckpt_output_dir="./grpo_output",
num_iterations=15,
group_size=8,
prompt_batch_size=100,
learning_rate=1e-5,
n_gpus=4,
)Orthogonal Subspace Fine-Tuning (OSFT)
OSFT is the algorithm that solves the continual learning challenge — fine-tuning a model on new tasks without destroying its existing capabilities. This was the focus of the live demo.
The JSON Output Problem

The presenters started with a concrete problem: the Qwen 2.5 1.5B Instruct model is capable but struggles with strict JSON output formatting — a common blocker for agentic AI applications that need structured responses. They demonstrated this with a table analysis task using cycling race data, asking the model to extract information and return pure JSON.
The base model produced valid JSON only 1% of the time. After OSFT fine-tuning on the TableGPT dataset, that jumped to 99%.
Live OSFT Training with MLFlow
The demo ran OSFT continual learning live on stage, tracking everything in MLFlow 3.12.0:
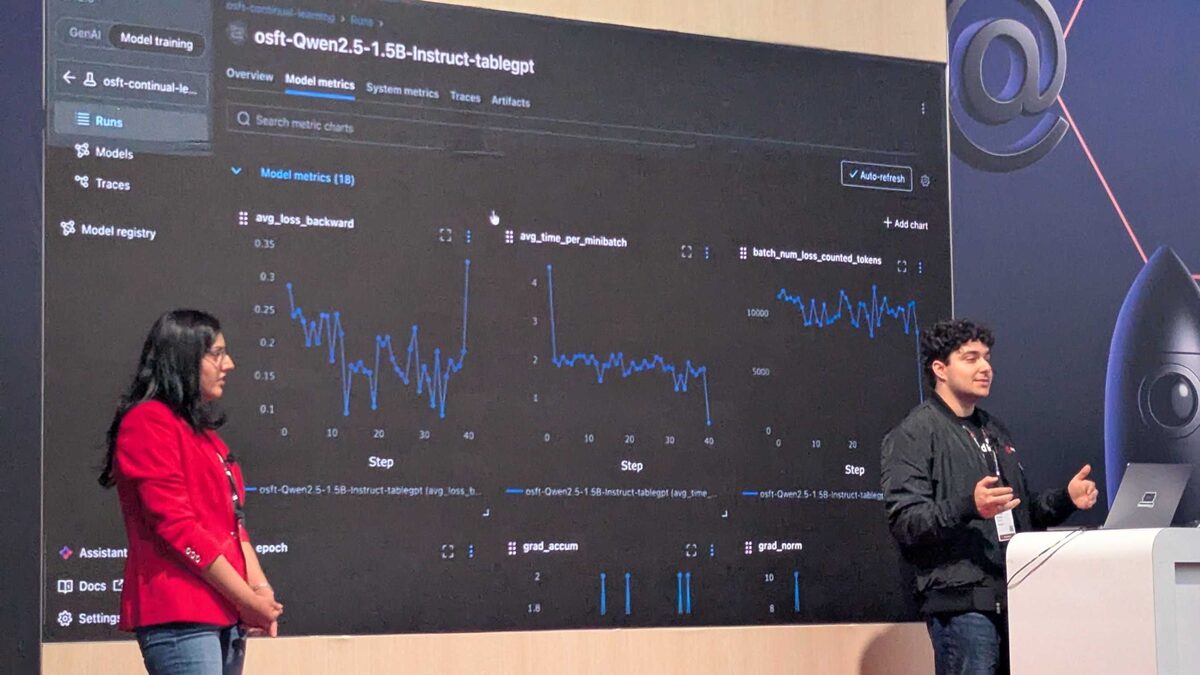
The MLFlow dashboard showed real-time metrics for the osft-Qwen2.5-1.5B-Instruct-tablegpt training run: loss curves dropping from 0.3 to below 0.1 over 50 steps, learning rate scheduling, and peak memory usage staying under 20 GB.
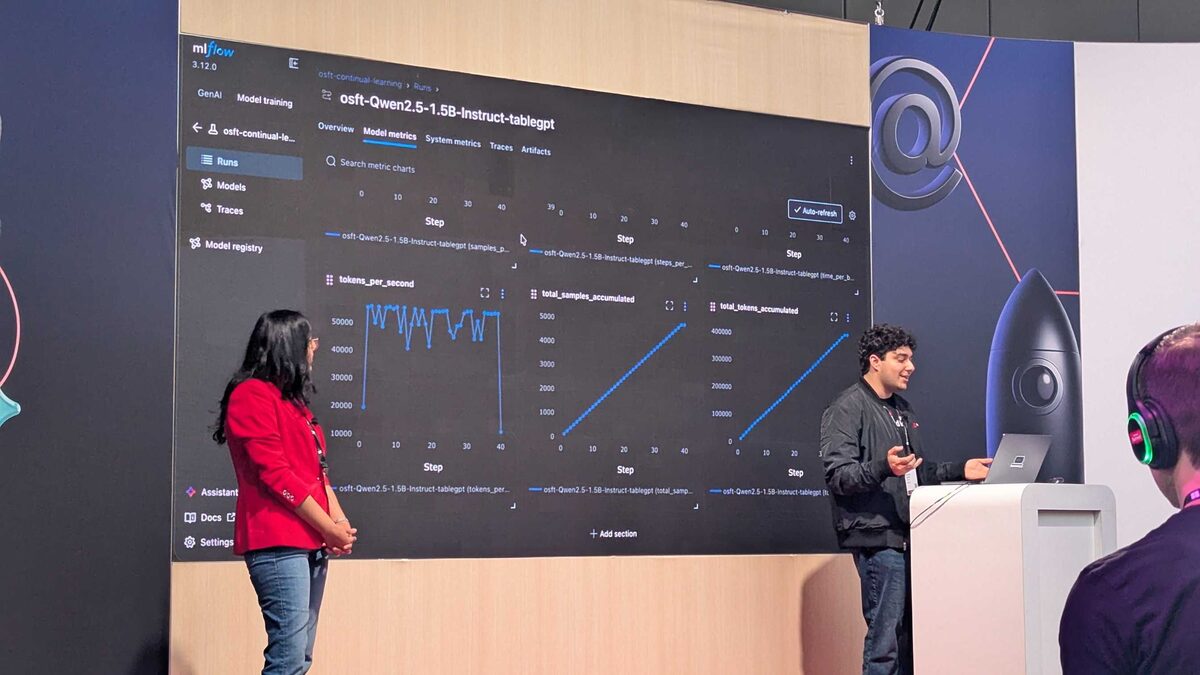
Additional metrics tracked: tokens per second (peaking at 50,000), total samples accumulated, and total tokens accumulated reaching 400,000 — all visible in the MLFlow experiment tracking UI with auto-refresh enabled.
MMLU Benchmark: Capability Preserved

The critical result: after OSFT fine-tuning, the model maintained over 99% of base model performance across all MMLU benchmarks. Categories like humanities (73.3%), international law (77.3%), machine learning (88.0%), medical genetics (81.0%) — all preserved within 1-2 percentage points of the original. The conclusion confirmed that OSFT solves the continual learning challenge: the model learned strict JSON formatting while keeping its general knowledge intact.
Platform Integration
Training Hub is not a standalone script — it integrates into the Red Hat AI platform:
- Red Hat Python Index — supported package, enterprise-grade distribution
- Kubeflow Training Operator — native integration for Kubernetes-scale training jobs
- Universal Workbench Image — pre-built container image for training environments
- MLFlow — native experiment tracking, model registry, and artifact management
Install with:
pip install training-hub[lora,grpo] # extras optional
pip install training-hub[cuda]Why This Matters
The AI industry has a fragmentation problem. Want to do SFT? Use one library. LoRA? Another. GRPO? Yet another. Each has different APIs, different configuration patterns, different ways of handling checkpoints and logging.
Training Hub eliminates this. One API surface, multiple algorithms, consistent behavior. Combined with the InstructLab SDG Hub for synthetic data generation and OpenShift AI for orchestration, Red Hat is building a complete open source AI training stack.
The fact that a 1B parameter model (Phi-4 Mini) can go from 1% to 99% JSON validity after fine-tuning on just 3x NVIDIA L40 GPUs is the real headline. You do not need a data center to build production-grade AI. You need the right tools.



