GitHub Copilot Business vs Claude Opus 4.5 Costs
I wanted the cleanest possible “vibe coding” setup: Copilot in the IDE, premium model on tap, minimal friction.
I got exactly that… right up until Copilot showed me this:
Premium requests: 418%
No outage. No broken pipeline. No failing tests. Just a meter I wasn’t watching, quietly converting my “premium vibes” into a line item.
This is my write-up, anchored on the numbers in my screenshots, plus the alternatives I’d pick if I wanted the same results for roughly the same budget.
1) What actually happened (numbers, not vibes)
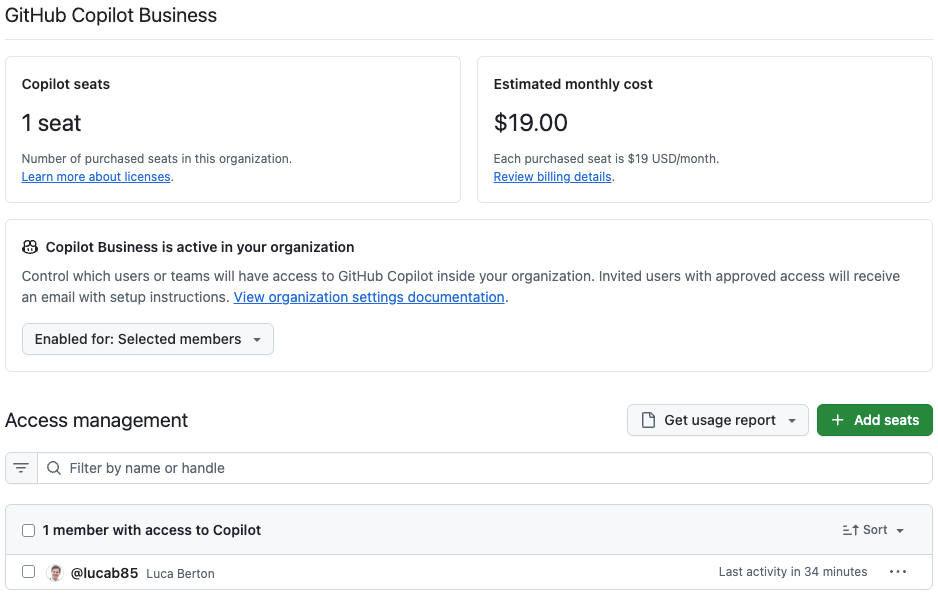
I’m on GitHub Copilot Business, 1 seat, and GitHub shows $19/month for the seat.
But my month wasn’t just the seat.
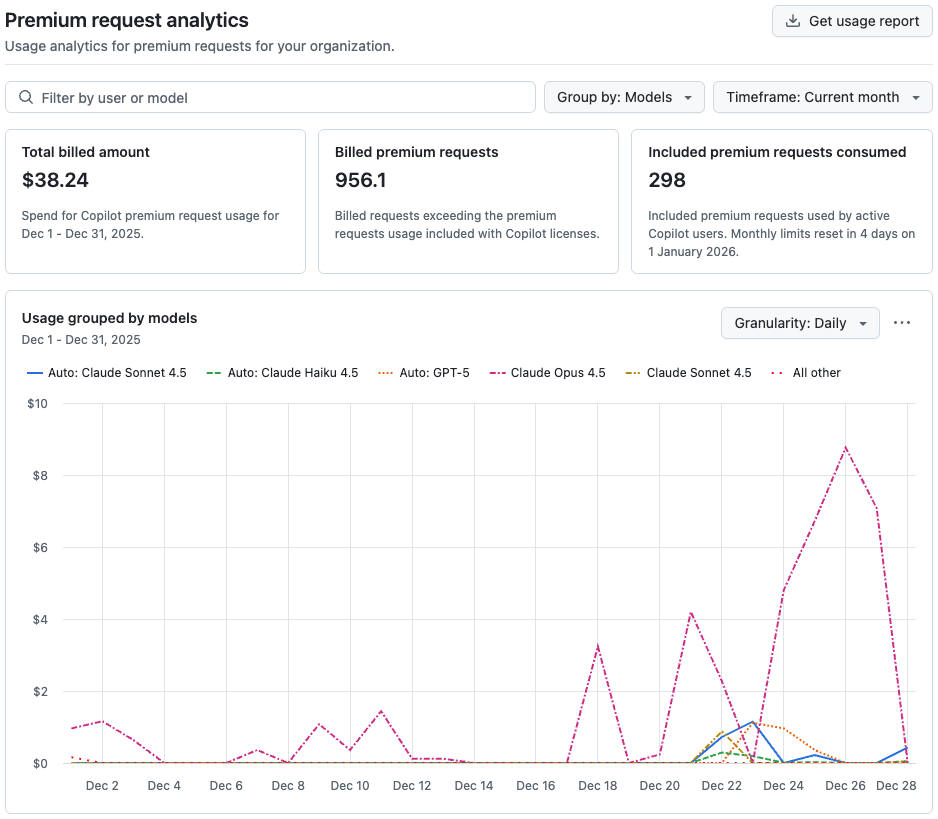
From Copilot’s Premium request analytics (Dec 1–31, 2025), I can see:
- Included premium requests consumed: 298
- Billed premium requests: 956.1
- Total billed amount (premium overage): $38.24
So I used about:
- Total premium requests: 298 + 956.1 = 1254.1
- That maps perfectly to the big scary bar: 418% (about 4.18× a 300-request allowance)
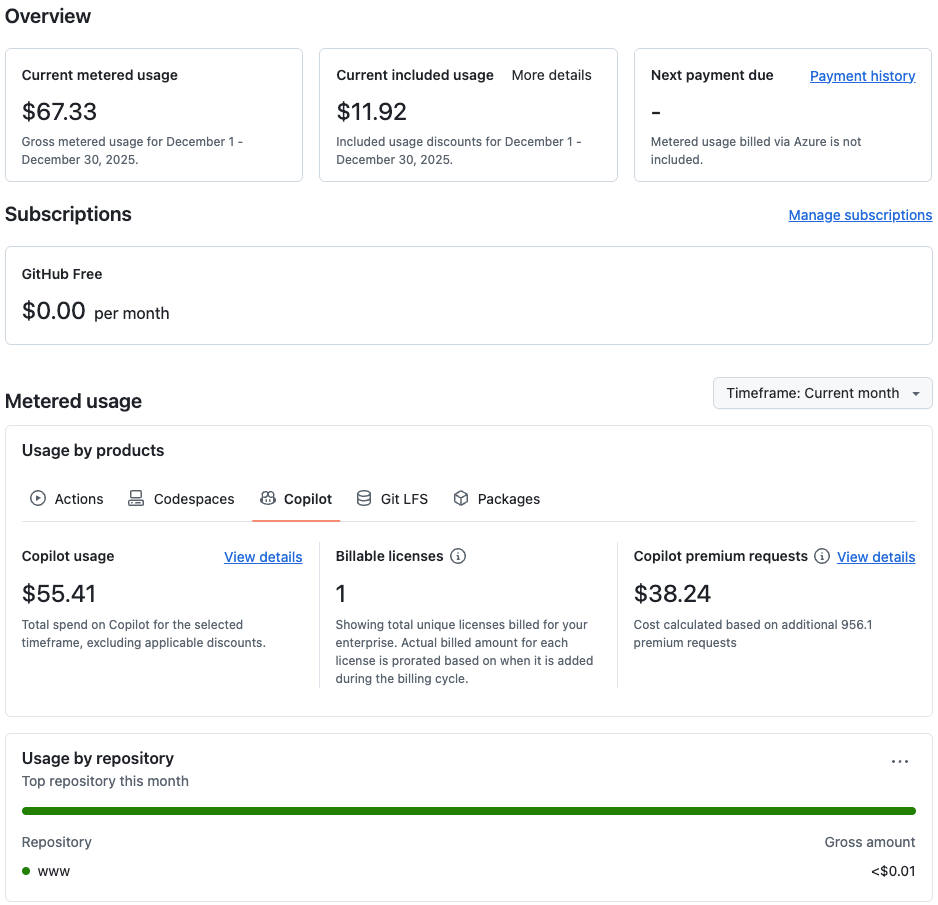
Then in the billing overview, GitHub shows:
- Copilot usage (net): $55.41
- Copilot premium requests portion: $38.24
Translation: this month, I didn’t just buy “Copilot.” I bought Copilot + a lot of premium overage.
2) Why this happened: Opus 4.5 is a multiplier machine
The part I underestimated is that Copilot premium usage isn’t “tokens.” It’s premium requests, and models have multipliers.
In GitHub’s model table:
- Claude Opus 4.5 = 3×
- GPT-5.1-Codex = 1×
- GPT-5.1-Codex-Max = 1×
- Some models are 0× (included) on paid plans
So every time I used Opus 4.5, I was basically spending 3 premium requests per prompt.
That’s also why my “usage grouped by models” chart is basically the Opus 4.5 line doing cardio while everything else barely moves.
3) What “418%” really means for my workflow
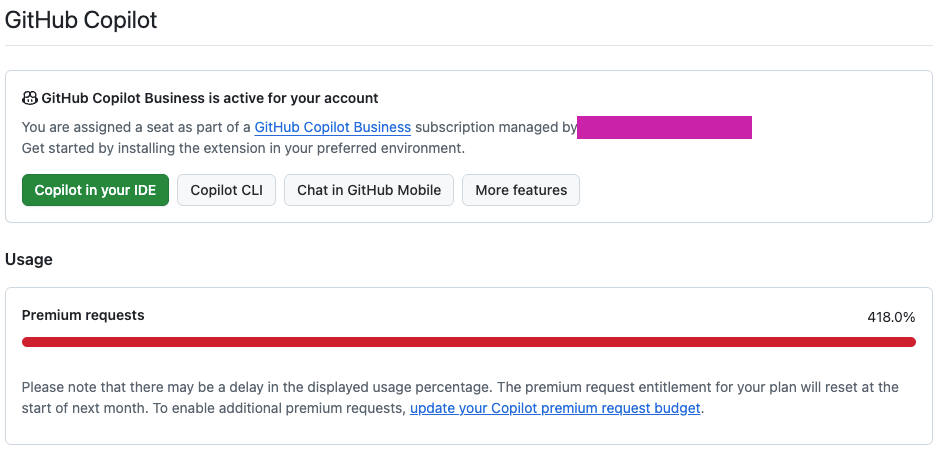
If I simplify the math:
I used ~1254 premium requests total.
If those were mostly Opus 4.5 prompts (3×), that’s roughly:
- 1254 ÷ 3 ≈ 418 Opus-style interactions for the month.
On Business, once I burn through the included allowance, every extra premium request costs money. Business overage is $0.04 per premium request.
So post-allowance, an Opus 4.5 interaction effectively costs:
- 3 × $0.04 = $0.12 per prompt (just in premium overage terms)
It’s not “expensive” per prompt… but it’s perfectly designed to become expensive when I’m in the flow.
4) The part I actually care about: alternatives for the same budget
My net Copilot spend in the billing view is about $55.41 this month.
So I asked myself: What else could I get for ~$55/month if the goal is premium coding output?
Here are the options I’d seriously consider.
Alternative A: Stay on Copilot Business, switch my default to GPT-5.1-Codex-Max (or GPT-5.1-Codex)
Both GPT-5.1-Codex and GPT-5.1-Codex-Max are 1× premium models in Copilot.
If I replay my month’s behavior but change only the multiplier:
- My ~418 “Opus interactions” would look like ~418 premium requests instead of 1254.
- With a ~300 request allowance, I’d only be ~118 requests over.
- Overage would be ~118 × $0.04 ≈ $4.72
- Total: $19 + $4.72 ≈ $23.72/month (ballpark)
Same IDE convenience. Same flow. A fraction of the “418%” panic.
This is probably the single highest ROI change I could make.
Alternative B: Use cheap premium models for most prompts (0.33×), then Opus only when it matters
If I still want “premium” but I don’t want to finance Opus as my daily driver:
- GPT-5.1-Codex-Mini = 0.33×
- Claude Haiku 4.5 = 0.33×
At 0.33×, my 300 included requests behave like ~900 prompts of runway.
My ideal split would be:
- 70–80%: 0.33× model for drafts + quick iterations
- 20–30%: 1× model for “serious coding”
- 5–10%: Opus 4.5 for the “this must be correct” moments
That keeps my brain in flow and my bill out of the red zone.
Alternative C: Use included (0×) models for routine work, and treat premium models like a power tool
Copilot also offers “included” models on paid plans that don’t consume premium requests (0×).
So I can do:
- everyday chat / lightweight help: 0× included model
- deep code help: GPT-5.1-Codex-Max (1×)
- heavy reasoning / architecture: Opus 4.5 (3×)
This is “cost-aware by default” without switching products.
Alternative D: Upgrade to Copilot Enterprise if I’m going to keep using Opus a lot
Copilot Enterprise is $39/seat/month and includes 1000 premium requests.
If I repeat my month (~1254 requests):
- Overage becomes ~254 requests
- Overage cost ≈ 254 × $0.04 ≈ $10.16
- Total ≈ $49.16/month
That’s actually lower than my ~$55 month on Business, and it buys me headroom.
If I’m not willing to change my prompting habits, Enterprise is the cleanest “don’t change my workflow” answer.
5) The AI Foundry option: token billing instead of request billing
What I really like about AI Foundry / API usage is that it’s token-shaped rather than request-shaped.
For OpenAI’s gpt-5.1-codex and gpt-5.1-codex-max, the published pricing is:
- $1.25 / 1M input tokens
- $10 / 1M output tokens
For a rough feel, assume a typical coding interaction is:
- ~2,000 input tokens (context + prompt)
- ~1,000 output tokens (answer + code)
That’s about $0.0125 per interaction.
With a ~$55 budget:
- ~$55 / $0.0125 ≈ 4,400 interactions (very rough, but directionally useful)
The point isn’t the exact number—it’s that Codex on tokens can be shockingly cost-efficient if I keep prompts reasonably sized.
And the flip side is also true: if I routinely paste massive files/logs, token bills climb fast. Token billing is predictable, but it makes my “context habits” visible.
6) What I’m actually going to do next month
If I want premium results without another “418%” moment, my plan is:
- Switch my default Copilot premium model to GPT-5.1-Codex-Max (1×)
- Use included 0× models for casual prompts
- Reserve Opus 4.5 for the rare “I need brilliance” prompts
- If I still blow past the allowance, I’ll stop pretending and move to Copilot Enterprise
- If I want maximum predictability, I’ll route my “big brain” prompts through AI Foundry / API and keep Copilot for IDE ergonomics
That’s the real lesson for me: Copilot is the best IDE UX, but Opus 4.5 is a premium tool—if I use it like a default, the meter will punish me.
If I stay intentional about when I use 3× models, I get the same quality and keep my budget boring.
📌 Need expert help with this topic?
Luca Berton
AI & Cloud Advisor with 18+ years experience. Author of 8 technical books, creator of Ansible Pilot, and instructor at CopyPasteLearn Academy. Speaker at KubeCon EU & Red Hat Summit 2026.