1) CI/CD can fail before it even starts
The most confusing part was that nothing “broke” in the codebase. The pipeline simply stopped executing:
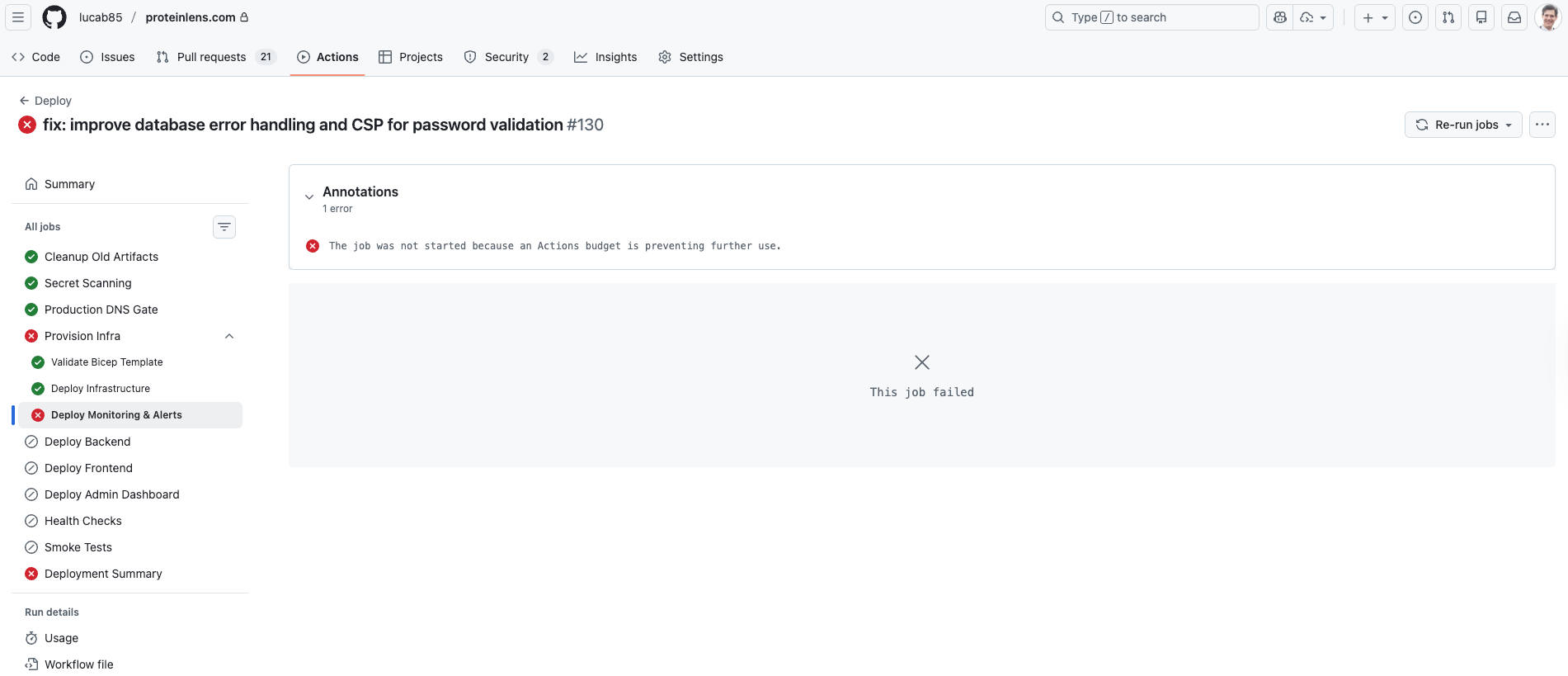
1 error The job was not started because an Actions budget is preventing further use. This job failed
That’s a different class of failure than a red build. It’s not a test failing, not an infra misconfiguration — it’s the platform telling you: you’re out of runway.
Lesson: treat CI/CD budget and quotas as production dependencies, not “admin settings.”
2) Fast iteration + monorepo = accidental amplification
Monorepos are great, but the default failure mode is expensive: one small change can trigger the whole world:
- infra validation
- secret scanning
- backend build + deploy
- frontend build + deploy
- admin build + deploy
- monitoring, alerts, health checks, smoke tests
Lesson: in a monorepo, CI/CD needs routing. If you don’t explicitly limit what runs, you’ll pay for everything every time.
3) Budget exhaustion is a system design signal, not just billing noise
When the pipeline couldn’t start, it forced a hard look at the operational shape of the project:
- CI/CD was becoming a bottleneck
- builds were ballooning
- deploys were too frequent and too coupled
- failures cascaded because there was no “safe mode”
Lesson: “Quota exceeded” is feedback. If your MVP can’t survive friction (CI minutes, rate limits, transient cloud failures), it’s not production-shaped yet.
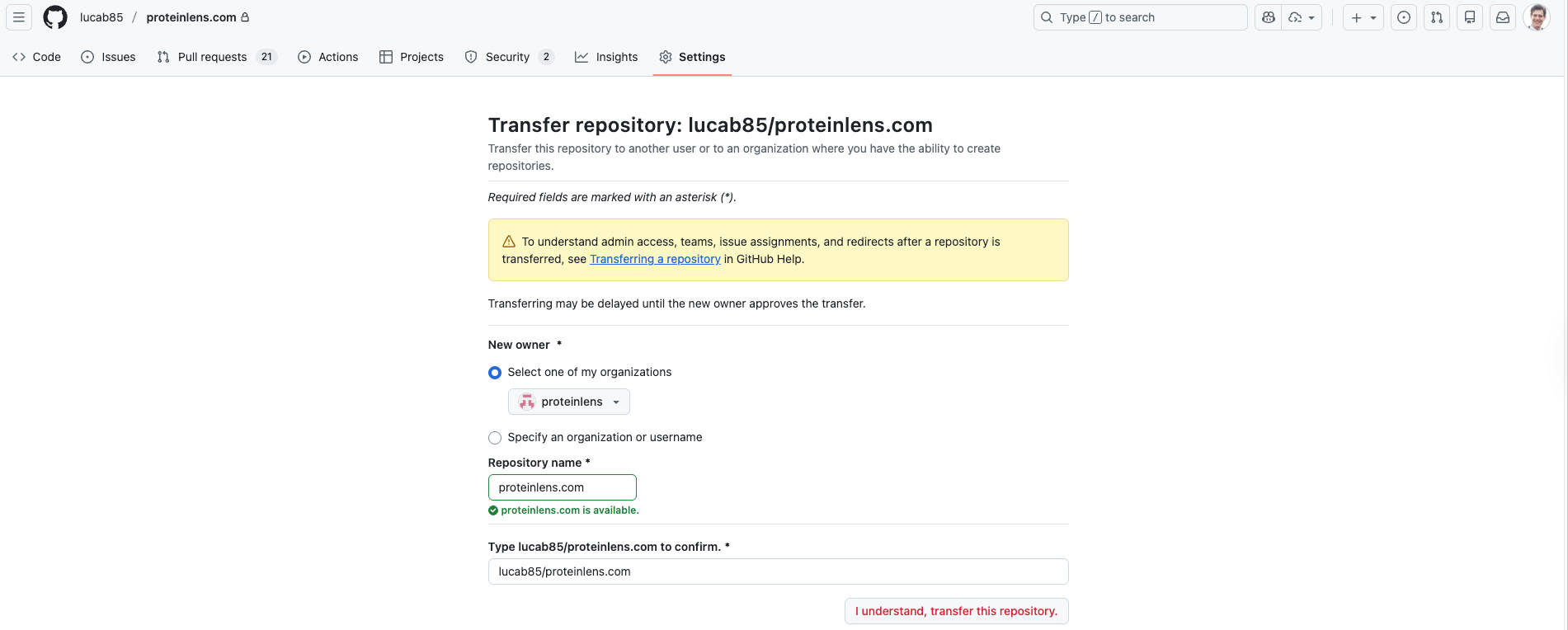
4) The fix wasn’t “optimize a workflow step,” it was changing ownership + billing model
The practical solution was to move the project under the organization so I could:
- connect an Azure subscription for billing
- centralize ownership, secrets, environments, and policies
- unlock org-level governance
- adopt GitHub Copilot Business
Concretely, I migrated the monorepo from:
lucab85/proteinlens.comto:proteinlens/proteinlens.com
Lesson: sometimes the best “technical” fix is an organizational change: who owns the repo, who pays, and what entitlements the project can use.
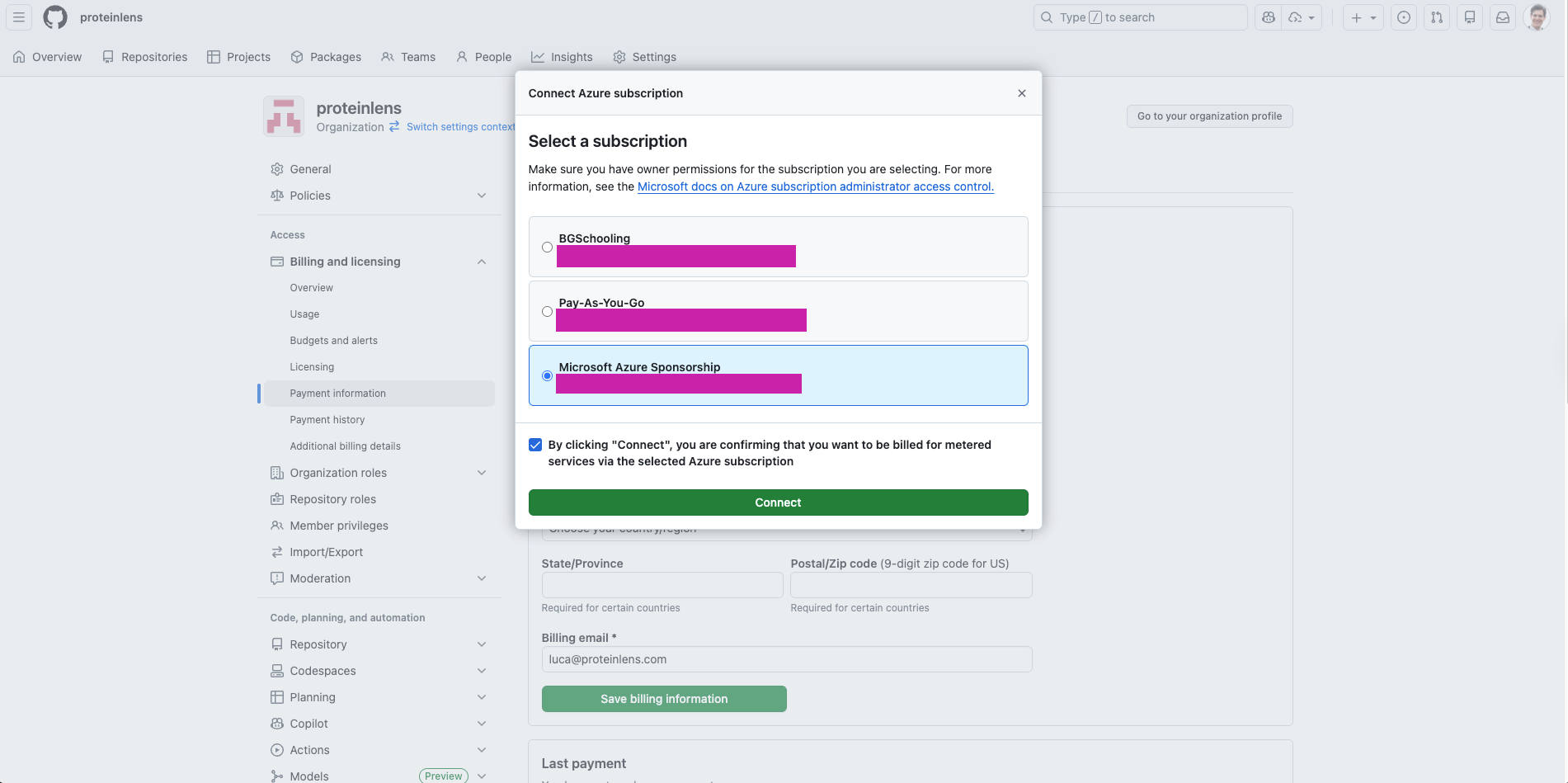
5) Azure subscription integration removes friction in the dev loop
Linking GitHub billing to Azure (especially when you already run your stack on Azure) keeps the dev workflow consistent: one cloud, one place to manage spend.
Reference: Connecting an Azure subscription https://docs.github.com/en/billing/how-tos/set-up-payment/connect-azure-sub
Lesson: aligning CI/CD spend with the same cloud subscription as your runtime spend reduces accidental limits and surprises.
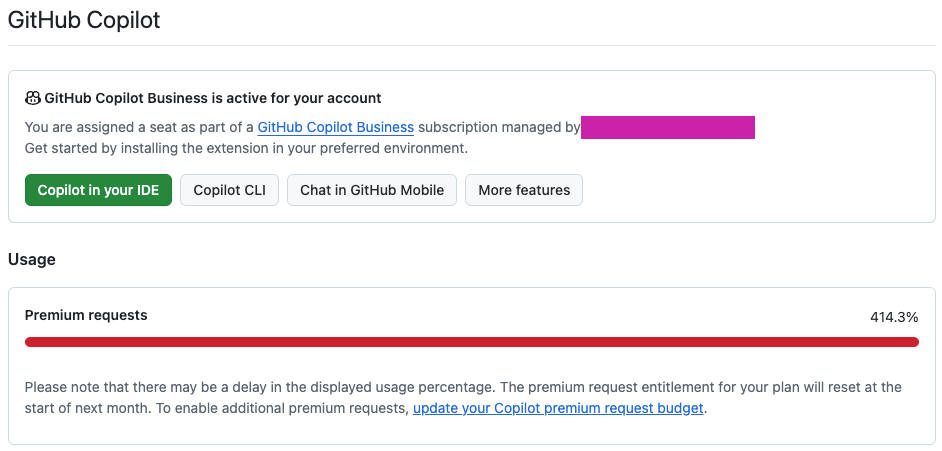
6) Copilot Business isn’t just “AI coding” — it’s an org capability
Moving to the org also means I can adopt GitHub Copilot Business in a way that’s manageable:
- centralized licensing
- policy controls
- consistent tooling across contributors
Lesson: tooling upgrades are easiest when the project lives where teams and billing live: the organization.
7) Post-mortem mindset: build guardrails that prevent silent runaway cost
After this, the concrete “engineering hygiene” actions became obvious:
- Path-based workflows (only deploy what changed)
- Concurrency (cancel older runs on new pushes)
- Caching (reduce build time)
- Separate PR checks from main deploys
- Failure isolation (infra deploy failing shouldn’t block unrelated app checks)
- Spend visibility (alerts when CI usage spikes)
Lesson: the best CI/CD is boring, predictable, and hard to accidentally abuse.
On Dec 25th I messaged a few friends: “I’m working on this project… if you want to put the site under pressure with some tests. It’s all on Azure. Merry Christmas!”
…and then reality showed up. Errors, quota limits, and eventually the one that made it painfully clear CI/CD is part of the product:
“The job was not started because an Actions budget is preventing further use.”
That turned into a mini post-mortem: not just “how do I unbreak deploys,” but how do I build an MVP that survives real usage and real constraints?


