
At the Community Central Theater at Red Hat Summit 2026, I watched one of the most important talks for anyone running LLM inference at scale: the llm-d project and why your load balancer is destroying your inference performance.
The numbers are stark: $0.30 vs $3.00 per million tokens. Same model. Same hardware. The only difference is whether your infrastructure is smart enough to use KV-cache.
Your GPU Is Re-Doing Work It Already Did

The presenter opened with a direct challenge: in production LLM inference, we track dozens of metrics, but one stands above the rest — KV-cache hit rate. KV-cache stores the Key and Value tensors from previous attention computations. It directly affects latency, throughput, and your bill:
- Cached token: $0.30 / M
- Uncached token: $3.00 / M
That is a 10x cost difference. Same model. Same hardware. The question is not whether caching matters — it is whether your infrastructure is smart enough to use it.

Why KV-Cache Matters

The Transformer inference loop has two phases:
- Prefill — process the entire input prompt, computing attention over every token pair (O(n^2)). This is where your GPUs sweat.
- KV-Cache — store the resulting Key and Value tensors. This is the model’s working memory.
- Decode — generate one token at a time (O(n)), reading and extending KV-Cache. This is cheap.
Prefill is expensive. Decode is cheap. Caching is the bridge.
Prefix Caching: Works on One Pod, Breaks on Two

For shared prefixes — common in conversational AI, agentic workflows, and RAG — the prefill is skipped entirely for subsequent requests. The presenter demonstrated this with a 10K token prompt on a Qwen3-32B instance:
- Cold (no cache): 4.3s TTFT
- Warm (cache hit): 0.6s TTFT
- Speedup: 7x faster, zero extra compute

This works beautifully on a single instance. The moment you add a second pod — it breaks.



The Scale-Out Problem

Here is the core problem that llm-d solves:
- In a multi-pod deployment, each vLLM instance manages its own KV-cache in isolation
- Standard load balancers route on utilization, round-robin, or latency — nothing cache-aware
- Related requests get scattered across pods, destroying cache locality

In a fleet of pods, this is not a rare event. It is the default behavior. Every time a follow-up message in a conversation hits a different pod, the entire prefix must be recomputed from scratch. That is 4.3 seconds instead of 0.6 seconds. That is $3.00 instead of $0.30 per million tokens.
What llm-d Does
llm-d is a Kubernetes-native inference gateway that makes load balancing KV-cache aware. Instead of blindly distributing requests, it:
- Hashes the prompt prefix to identify which pod already has the relevant KV-cache warmed up
- Routes the request to that pod, achieving cache hits across a multi-pod fleet
- Falls back intelligently when the cached pod is overloaded, balancing cache locality against queue depth
The result: you get single-instance cache hit rates across a horizontally scaled fleet. The 7x latency improvement and 10x cost reduction that prefix caching delivers on one pod — llm-d delivers across your entire cluster.
The llm-d Architecture: Three Planes
The presenter walked through the full architecture in detail. llm-d is organized into three planes:
Control Plane

The Control Plane installs Kubernetes CRDs, Gateway infrastructure, and service mesh. It provides guides to ensure cluster prerequisites are met and offers “Well Lit Paths” — opinionated deployment patterns. The main repository is llm-d/llm-d.
Routing Plane

The Routing Plane is the Inference Gateway built on the upstream Gateway API Inference Extension. The key component is the EPP (Endpoint Picker Plugin) — the llm-d-inference-scheduler that intercepts every request before it is forwarded and scores candidate pods. The scoring is KV-cache-aware and load-aware, using pluggable scorers. Related repositories:
Data Plane

The Data Plane is where the actual inference happens. Each pod manages its own KV-cache, and vLLM’s Automatic Prefix Caching identifies shared token prefixes and skips prefill. In a fleet, these isolated caches form a distributed KV-cache — the total cached state is spread across all pods. In the precise path, every pod continuously emits KVEvents giving the routing plane its view into this state.
Two Data Flow Modes: Precise vs Approximate
Precise Path
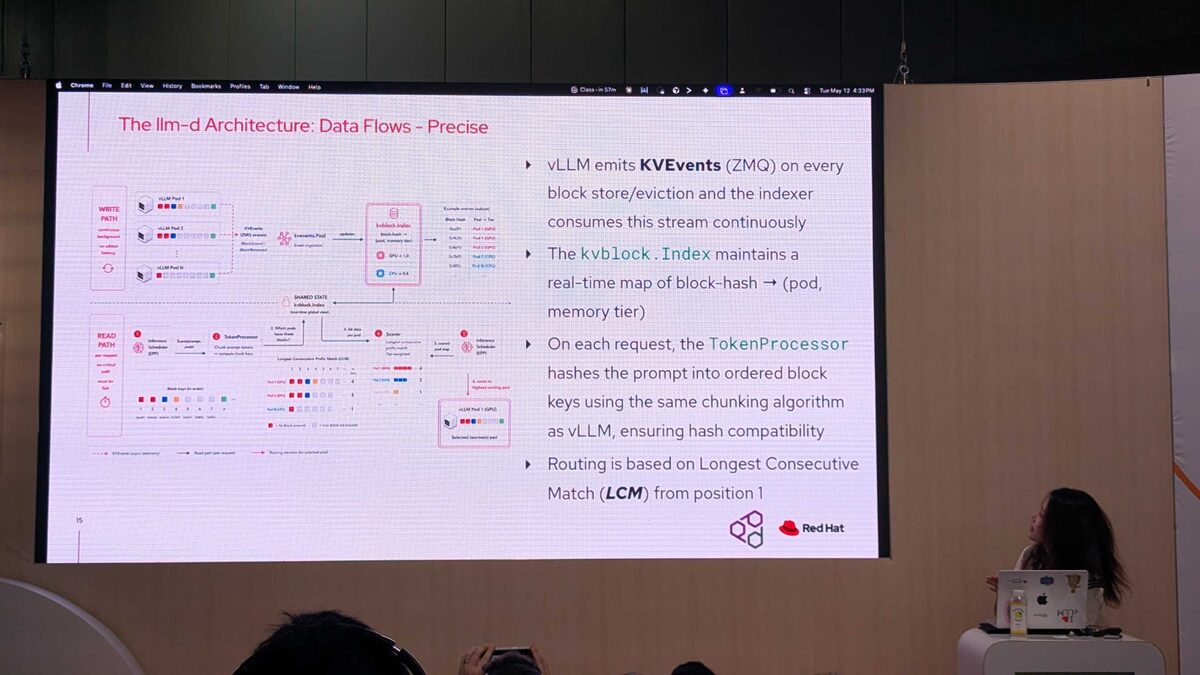
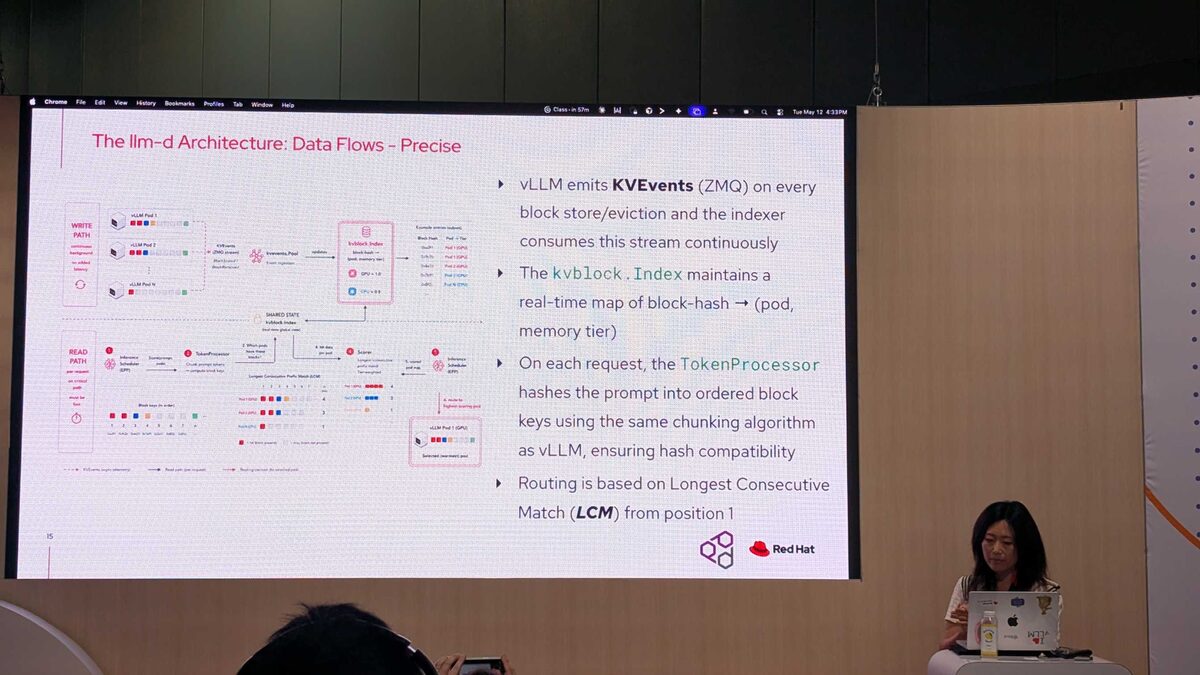
The precise path provides exact cache awareness:
- vLLM emits KVEvents (via ZMQ) on every block store and eviction
- The
kvblock.Indexmaintains a real-time map of block-hash to (pod, memory tier) - On each request, the
TokenProcessorhashes the prompt into ordered block keys using the same chunking algorithm as vLLM, ensuring hash compatibility - Routing is based on Longest Consecutive Match (LCM) from position 1
Approximate Path

The approximate path is simpler — no external indexer, no ZMQ stream. The PrefixStore lives entirely inside the EPP:
- After every routing decision,
PostSchedulerecords the pod-prompt association in an in-memory trie - On the next matching request,
PrefixAwareScorerqueries the trie and scores pods by longest prefix match - Prefix affinity is combined with
LoadAwareScorerandKVCacheUtilizationScorer

The approximate path trades precision for simplicity — no additional infrastructure components needed. The PrefixStore is an in-memory structure inside the EPP, meaning it resets on pod restart and has no persistence or cross-EPP replication.
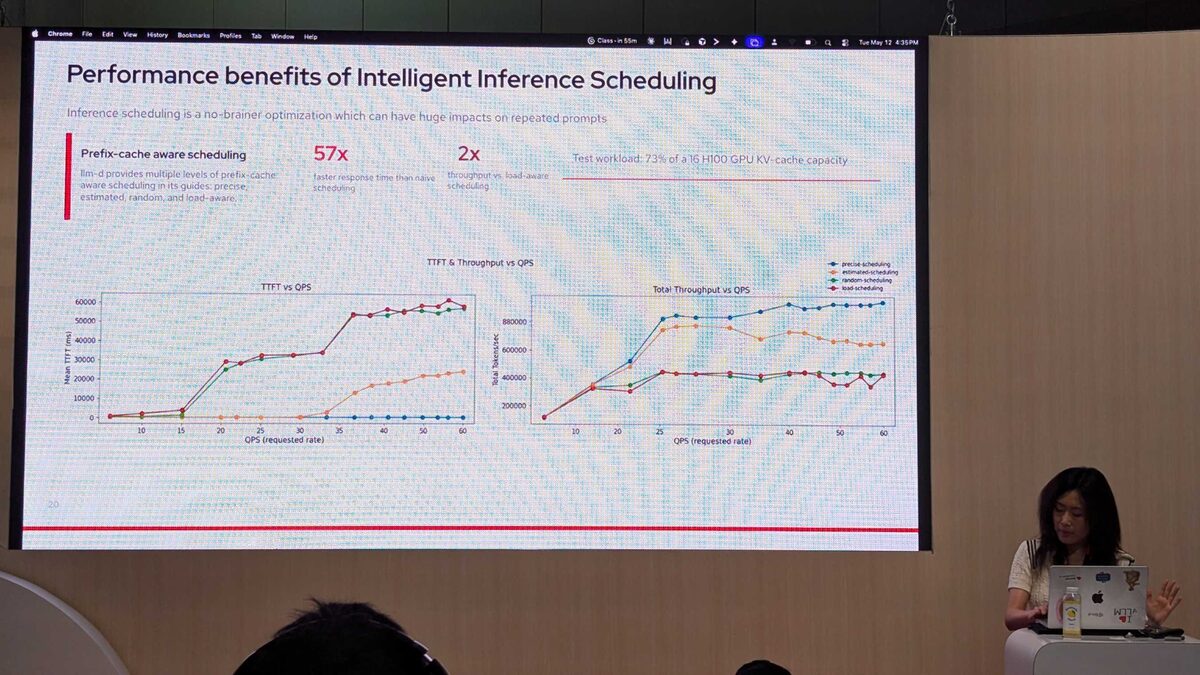
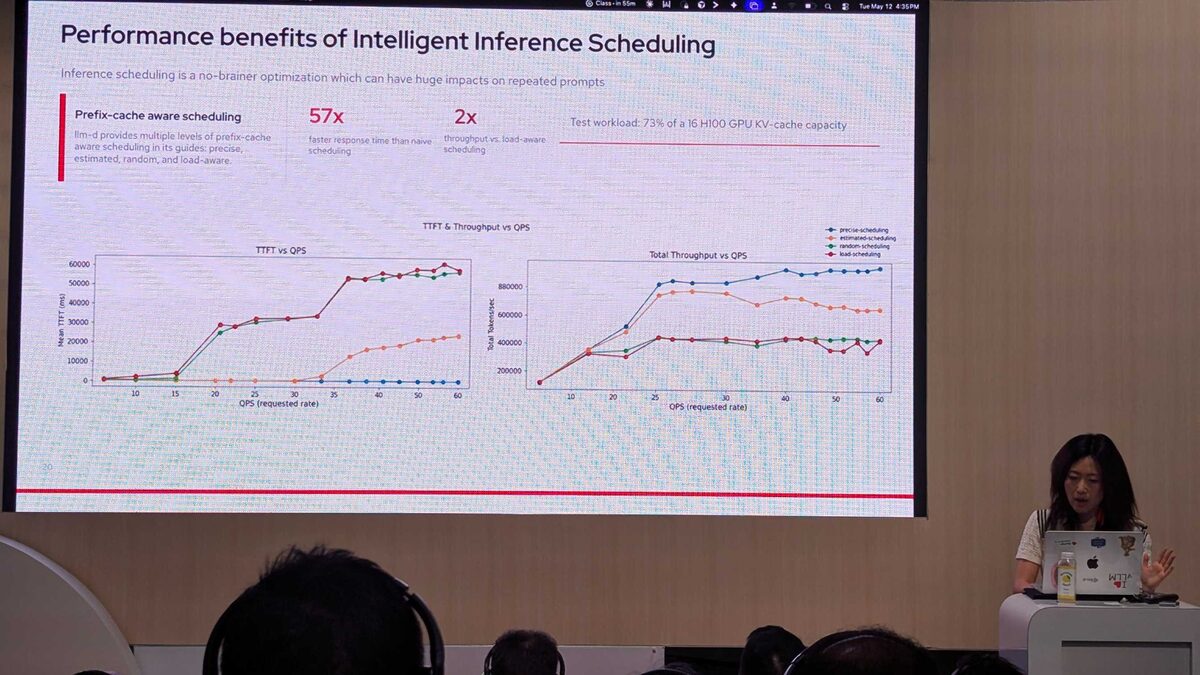
Benchmarks: 57x Faster, 2x Throughput

The benchmark results are stunning. On a test workload using 73% of a 16 H100 GPU KV-cache capacity:
- 57x faster response time than naive scheduling (precise scheduling)
- 2x throughput vs load-aware scheduling
- TTFT stays near zero for precise scheduling even at 60 QPS, while random and load-aware scheduling spike to 50,000-60,000ms
The TTFT vs QPS chart tells the story: precise scheduling (blue line) stays flat near zero across all QPS levels, while load-aware scheduling (red) climbs exponentially past 25 QPS.
Benchmark Setup

The benchmark simulated a realistic B2B scenario:
- 150 enterprise customers, 5 concurrent users each
- Each request shares 6K context tokens, adds 1,200 unique input tokens, and expects 1,000 output tokens
- 16x NVIDIA H100 GPUs in an 8x vLLM Qwen/Qwen3-32B TP=2 deployment
- Total KV-cache demand is 73% of cluster capacity, within the hardware limit

The key insight: because the workload fits within KV-cache capacity, cache-aware scheduling can win by placing repeated prefixes on the right pods. Full benchmark configuration details at llm-d.ai/blog/kvcache-wins-you-can-see.
Effective Cache Throughput

The Effective Cache Throughput metric measures prompt tokens per second served directly from cache instead of recomputed during prefill. The chart makes the hierarchy unmistakable:
- Precise scheduling peaks at 200,000+ tokens/sec from cache — massive spikes of cache hits
- Approximate scheduling reaches about 100,000-150,000 tokens/sec — still significant but with more variability
- Random scheduling barely registers at 25,000-50,000 tokens/sec — most prefill is recomputed from scratch
Precise scheduling creates the highest useful cache throughput under repeated-prefix load. This is the metric that directly translates to cost savings — every token served from cache is compute you did not pay for.
The Community Central Theater was packed for this session — headphones on, everyone leaning in. The combination of real benchmark data and a clear open-source path to implementation clearly resonated with the audience.
Why This Matters for Production AI
This talk crystallized something I have been seeing across enterprise AI deployments: the inference cost problem is not about the model or the hardware — it is about the routing layer.
Most organizations running multi-pod vLLM deployments behind a standard Kubernetes Service or Ingress are unknowingly paying 10x more than they need to. Every agentic workflow, every RAG pipeline, every multi-turn conversation is recomputing prefill because the load balancer does not understand KV-cache.
llm-d turns infrastructure from a cost center into a competitive advantage. And it is open source.



